回溯法求解数独问题
引言
起因是在leetcode上看到了这题:36. 有效的数独,这题其实是判断数独的初始盘面是不是有效的,即初始数字是否满足行、列和小方块里都不重复的条件。可以通过一次遍历解决。
1 | class Solution: |
因为数独的元素天生是数字,所以这里的counter实际上可以用数组表示。但为了方便使用in的语法,这里直接申请了集合,占用空间会大一些。
一开始看这道题的时候把我吓了一下,因为是做“有效的数独”,还以为要判断这个数独可不可解,解唯一不唯一才能判断“有效性”。看题面后发现是看初始条件有效就行了。那也引发一个问题,如果真的要解数独,或者要判断这个数独题目可不可解有办法做吗?
回溯法及框架
学过的算法加解题的技巧就下面几种: 1. 分治法(Divide-and-conquer method, DC) 2. 二分查找(Binary seach) 3. 双指针(Double point) 4. 滑动窗口(Sliding Window) 5. 贪心法(Greedy algorithm) 6. 动态规划(Dynamic promgraming, DP) 7. 回溯法(Backtracking)
因为不是查找问题,所以2,3,4可能都用不了。贪心法和动态规划一般用于求解最优化的问题,这里似乎也不太好用。分治法因为数独行、列和小方框之间都有联系,似乎不太好分治。因此选择回溯法去做,通过深度优先搜索和回溯来查找数独题面的可行解。
引用一下wiki上的解释:
回溯法(英语:backtracking)是暴力搜索法中的一种。
对于某些计算问题而言,回溯法是一种可以找出所有(或一部分)解的一般性算法,尤其适用于约束满足问题(在解决约束满足问题时,我们逐步构造更多的候选解,并且在确定某一部分候选解不可能补全成正确解之后放弃继续搜索这个部分候选解本身及其可以拓展出的子候选解,转而测试其他的部分候选解)。
在经典的教科书中,八皇后问题展示了回溯法的用例。(八皇后问题是在标准国际象棋棋盘中寻找八个皇后的所有分布,使得没有一个皇后能攻击到另外一个。)
回溯法采用试错的思想,它尝试分步的去解决一个问题。在分步解决问题的过程中,当它通过尝试发现,现有的分步答案不能得到有效的正确的解答的时候,它将取消上一步甚至是上几步的计算,再通过其它的可能的分步解答再次尝试寻找问题的答案。回溯法通常用最简单的递归方法来实现,在反复重复上述的步骤后可能出现两种情况: - 找到一个可能存在的正确的答案 - 在尝试了所有可能的分步方法后宣告该问题没有答案
在最坏的情况下,回溯法会导致一次复杂度为指数时间的计算。
上算法课的时候老师总结了一个好用的回溯法思考框架:
1 | ''' |
其辅助函数的实现:
1 | def nextAdj(v, e): |
简单解释一下各个部分的含义:
- 函数
dfs(v):dfs是深度优先搜索(Depth First Search)的缩写。v是当前的部分解,即一个从起始状态到当前状态的路径或部分解集。
- 函数调用
advance(v):- 这是一个占位符函数,通常用于在进入下一个递归调用前做一些初始化或准备工作。在具体实现中,可能包括更新状态、打印调试信息等。
- 条件检查
isLeaf(v):- 检查当前部分解
v是否已经达到叶子节点。叶子节点通常表示一种完全解或一种可接受的终止状态。 isLeaf(v)函数定义了叶子节点的判定标准。例如,在排列问题中,当v的长度等于待排列元素的数量时,v就是一个叶子节点。
- 检查当前部分解
- 函数调用
remark(v):- 这是另一个占位符函数,通常用于处理或记录找到的完整解。例如,打印解、存储解或其他处理操作。
- 获取下一个邻接节点
e = nextAdj(v, None):nextAdj(v, None)函数用于获取当前部分解v的第一个邻接节点。对于第一个调用,e通常被初始化为None。- 在具体问题中,邻接节点表示可以扩展当前部分解的下一个可能选择。
- 边界检查
if not exceedBound(v + [e]):- 检查扩展后的部分解
v + [e]是否超过了问题定义的边界条件。 exceedBound(v + [e])函数定义了部分解的有效性标准,如果扩展后的部分解无效,则跳过当前节点e。
- 检查扩展后的部分解
- 回溯
backtrack(v):- 如果所有邻接节点都处理完毕或找到一个有效解后,进行回溯操作,即从当前部分解
v中移除最后一个元素,以便返回到上一步状态。 backtrack(v)函数通常包括从v中删除最后一个元素,并可能进行一些其他恢复操作。
- 如果所有邻接节点都处理完毕或找到一个有效解后,进行回溯操作,即从当前部分解
简单来说就是通过深度优先搜索暴力地遍历完所有解的空间,期间通过边界检查剪掉不合理的分支缩小查找范围。
回溯法求解数独
有了上面的铺垫,求解数独的问题可以分解为以下流程:
- 先判断盘面是否合理,盘面不合理就退出。
- 试探性地在未解决的位置填入数字,并考虑下一个未解决的位置。
- 如果下一个位置没有任何可填的数字,则回溯到上一个决策点重新决策。
- 如果已经没有未解决的位置了,就说明已经找到解了,输出解。
实现之后:
1 | # 通过回溯法求解数独的解 |
拿wiki上的题目测试一下:
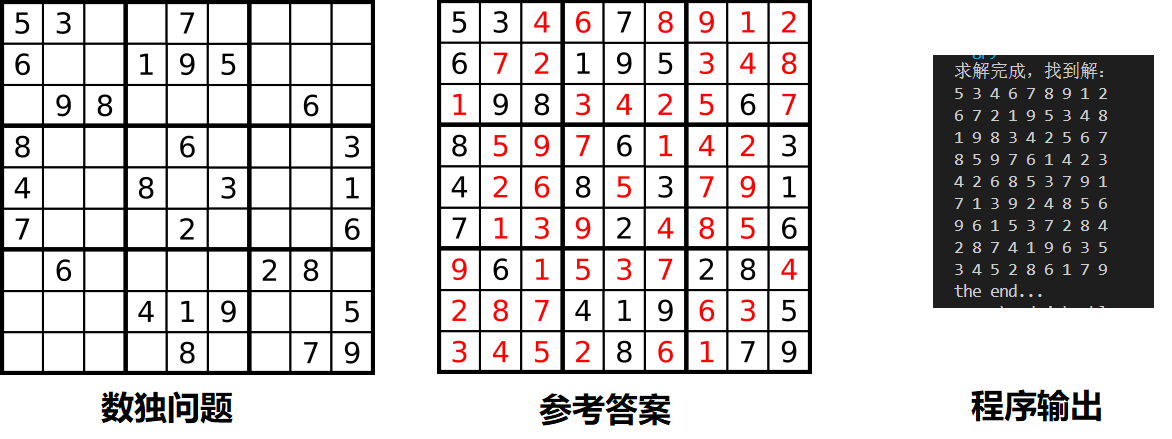
可以发现结果是没问题的,再测试一道题:
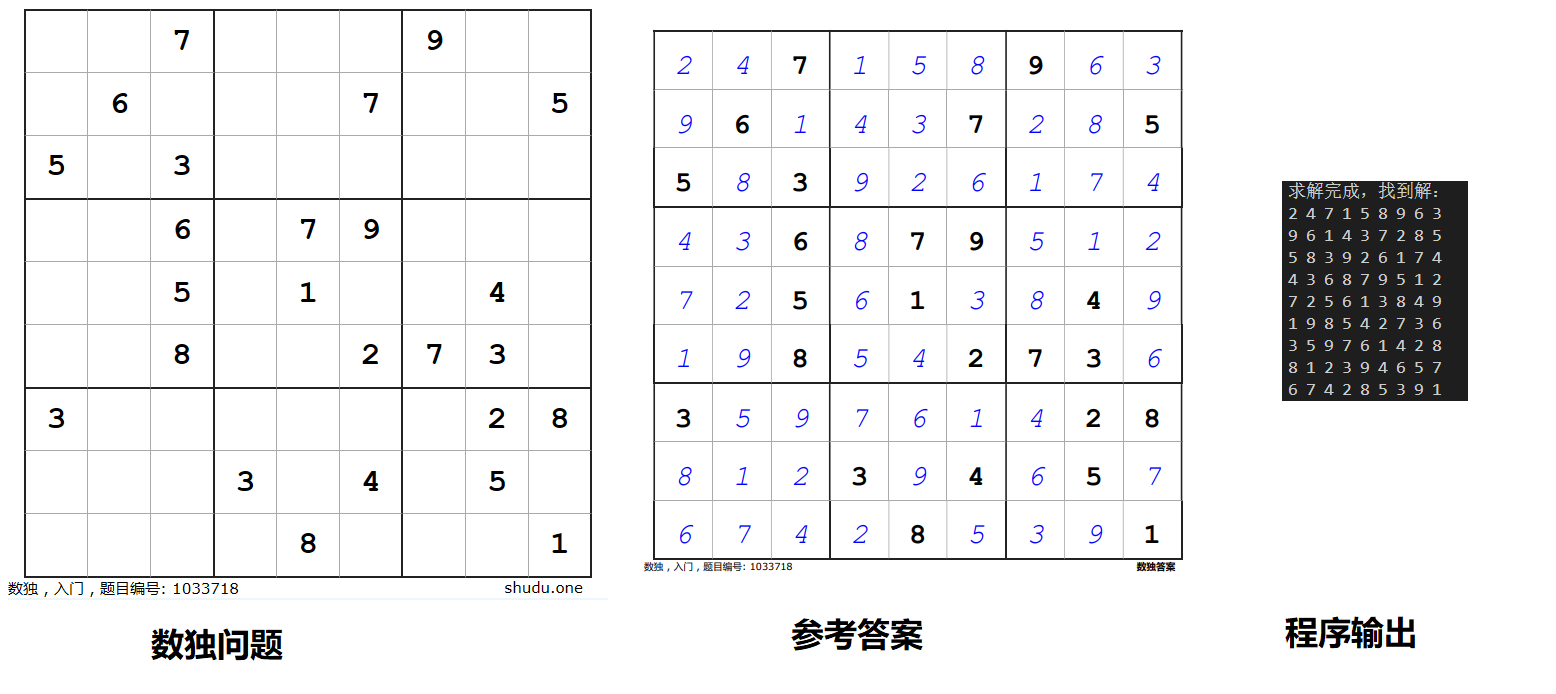
结果也没有问题。
然后这样,用回溯法解决数独问题的程序就写好了。
优化思路
现在的代码已经可以解决数独问题了,但逻辑是通过依次向未知位置试探性填入数字做到的。这里面没有用到盘面的先验信息,每次都从最前面的未知位置开始填,填错了就回溯直到遍历完所有空间。
这显然有点不符合人做数独的逻辑,人做数独肯定是要观察盘面的,不然数独题也不会有入门、简单、困难这样的难度划分。以第一个数独例子来说,如果我们按顺序先填红色箭头的位置,则可以填1,2,4三个数,这里就有3个分支。但如果我们先填蓝色箭头的位置呢?蓝色箭头的位置以及有很多约束条件了,只能填4,只有一个分支,不需要在这里进行回溯了。
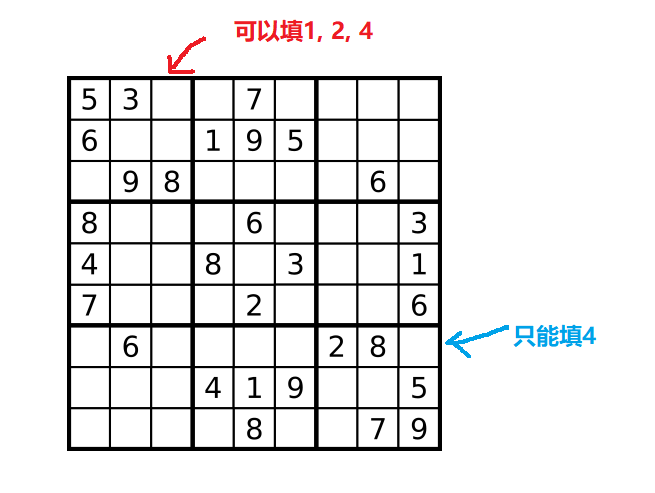
问题就转化为了:如何启发式地选择决策点,使得回溯的次数最少?
这样可以缩小搜索的空间,从而提升算法效率(当然回溯法最坏情况一定是指数的,这里的效率是指的回溯的次数)。
其实可以看出,一个点的难易程度可以用现在可用的解空间描述。可以用一个优先队列来维护盘面信息,以解空间的大小做一个优先队列,优先弹出解空间小的未知位置做决策。
1 | # 通过回溯法求解数独的解 |
主要区别就是通过fs_space变量来考虑初始盘面信息了,先从可填的解少的地方开始填起。
为了比较优化前后的区别,通过backtracing_num来记录找到可行解前的回溯次数。同样求解示例1和示例2,打印优化前后的回溯次数:
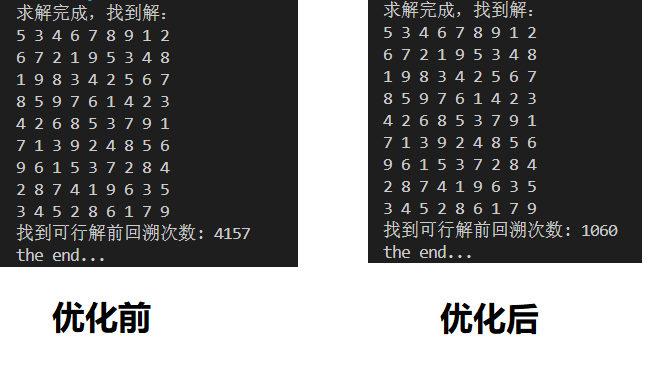
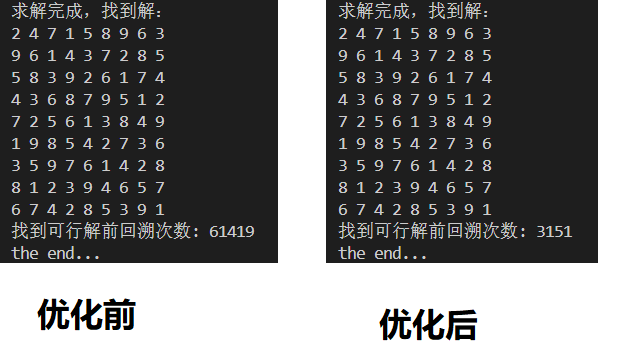
可以看到,对于案例1回溯次数减少到原来的1/4,而案例2则减少到原来的近1/20了。这说明考虑盘面信息先验可以有效地减少回溯的次数。
但代价是什么呢?构建和维护这样的优先队列也是要时间的。但好在构建优先队列大约花费O(nlog n)复杂度,而每次回溯把元素插回去消耗O(log n)复杂度,相比指数复杂度影响不大。(n是待求解元素总数)
也可能会进一步地想,要是每次决策也同时考虑这次决策给其他未求解格子的可行解空间造成影响,动态考虑盘面可不可行呢?应该也是可行的,倒不如说这样更符合人类的决策习惯。但是优先队列一个问题就是插入元素后不好更改优先级,会破坏堆结构内部的顺序。如果不用堆结构,那每次获取待决策位置都会产生开销,这里有点不好。
因此,为了整体结构的简洁性,放弃动态考虑整体盘面,而是直接初始盘面用到最后。
总结
通过数独求解,回顾了回溯法的流程和编程框架。