细节处见真章——LLM中的tokenizer
在大语言模型中,tokenizer(分词器)是一个非常关键的组件。它的主要功能是将输入的文本数据转换为模型能够处理的格式,通常是一个序列的token(标记)。具体来说,tokenizer将文本分割成较小的单位,通常是单词、子词或字符,这些单位称为token。
tokenizer的特征
tokenizer的作用非常直观,就是将文本分割成一系列token。好的tokenizer应该具备两个特征: 1. 高压缩率,以实现高效推理。 2. 适当大小的词汇表,以确保每个token都被充分训练,不会出现非常低频欠训练的token。
PS: 之前可能还有一个就是要保证覆盖,即减少训练时<UNK>标记出现的概率。但是现在基本使用BBPE编码技术,将文本处理为字节级别的序列。任何unicode字符都由1-4个字节构成,这意味着只要LLM词表覆盖了所有unicode的字节(只有2^8=256个),理论上任何unicode字符都不会被编码成<UNK>了。现代的LLM基本不存在未见词(Out-of-Vocabulary, OOV)的问题了。
鱼和熊掌不可兼得
这两个特征看似简单,但是二者其实是矛盾的。因为高压缩率,如何提高压缩率呢?一是将高频的、长的词编入词表;二是扩大词表的大小。这样语料整体的token就会变少,一旦稀疏到一定程度,在训练数据中就有token没有出现足够多次数,导致模型对这个token欠训练。
举个例子,比如“太阳能”作为一个token,比“太阳”和“能”2个token组合表示压缩率更低。然而这样“太阳能”作为一个独立的token就失去了“太阳”和“能”的加持,模型必须要从显式提到“太阳能”字眼的语料中学习它的意思,而无法根据“太阳”和“能”这两个token推断其意思。
因此好的tokenizer应该在两者之间取得平衡,即保持很好的压缩率,以便在自回归token by token的框架下取得较高的推理效率,同时也要考虑预训练语料中token的分布,避免出现很稀疏、欠训练的token影响模型性能。
好的tokenizer能提升上下文长度
这其实算是一个副作用。我们考虑一个极端的场景,假设一个只处理纯英语的LLM,它的词表其实支持acsii码的128个字符就可以处理所有的英文语料的训练和推理了。但带来的问题是什么?
首先能想到的就是低效的推理,每个token就是一个字符,所以是一个字母一个字母出的结果。
其次就是这个LLM使用时能明显感觉它的上下文比其他LLM短!因为其他LLM一个token可能就相当于4个字母了,这个LLM才1个字母。所以如果同样4K长度支持的LLM,拥有优秀tokenizer的LLM不仅具有更快的推理速度,在用户感知层面也会觉得这个LLM支持的上下文更长而且更便宜。
在多语言环境里,这个问题就更加复杂。因为即使在多语言的条件下,不同语言的语料数量也是存在很大差距的,“好的tokenizer”当然会优先照顾高资源语言。虽然现在LLM的词表大小都不小,但是不同语言用户用着体验非常不同。有的语言用户可能说一句“你好”就占据大量的上下文窗口了。gpt-4o尝试解决这个问题,但似乎小小翻了个车,后面一起来讨论一下。
污染还是有细节?
关于gpt-4o新的tokenizer,openai自己是这样描述的: > These 20 languages were chosen as representative of the new tokenizer's compression across different language families
大概20种语言都有更好的压缩率了,多的甚至有4倍左右的token减少;中文也还行,同一句话的token减少1.4倍。这配合4o比4turbo便宜50%,可以计算相同的中文任务,4o在tokenizer增强下,实际费用为: \[ 1 * 0.5 / 1.4 \approx 0.3571 \] 即gpt-4o中文任务上实际成本是gpt-4turbo的35.71%,相当于打6折还要多,这可以算是相当恐怖了。
但很快就有人发现词表翻车了,参见链接:github上的讨论。
国内有人将这个问题归结为训练tokenizer时语料没洗干净,导致中文出现了很多广告token。其实这个问题深入思考,“语料污染”这个说法对,也不对。
首先说对的一方面,tokenizer完全是通过统计训练tokenizer的语料来决定哪些模式被选入词表的。如果“免费视频在线观看”这样的序列都变成token了,说明这个序列在训练tokenizer的语料里反复出现。所以说语料污染,至少在训练tokenizer的训练语料中是存在的。
然后说不对的一方面。有人认为这个问题反映的是openai不重视中文,洗语料的能力倒退了。我感觉这是不靠谱的,原因有两个,一是gpt-4o在中文的榜单上表现依旧强势,个人体验4o也是又快又好。这说明训练gpt-4o本体的语料是没问题,否则很难想象在充满广告的语料里openai用什么黑科技让gpt-4o有这样好的表现。而且目前LLM预训练语料都有严格的去重清洗流程,重复度很高的广告很容易就被清洗掉了。
二是混进去的奇怪token在测试时表现出明显的“欠训练”性质,比如:
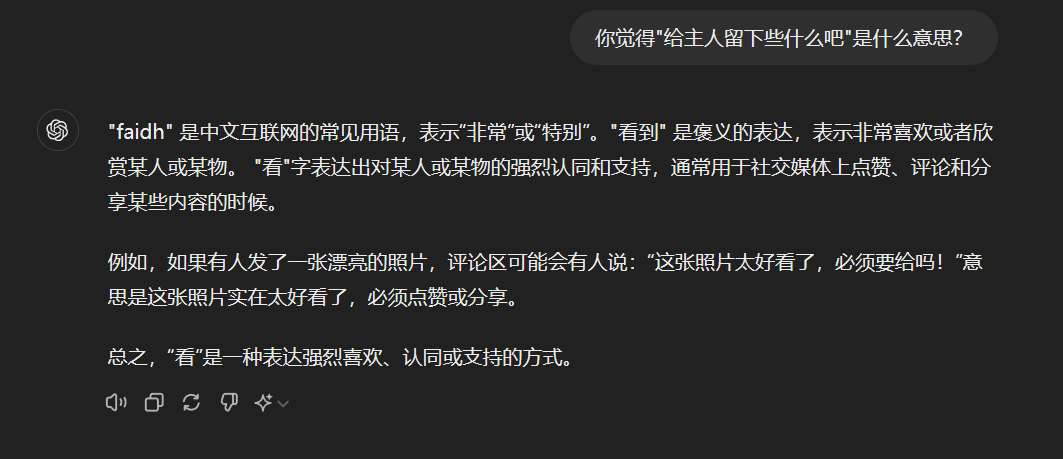
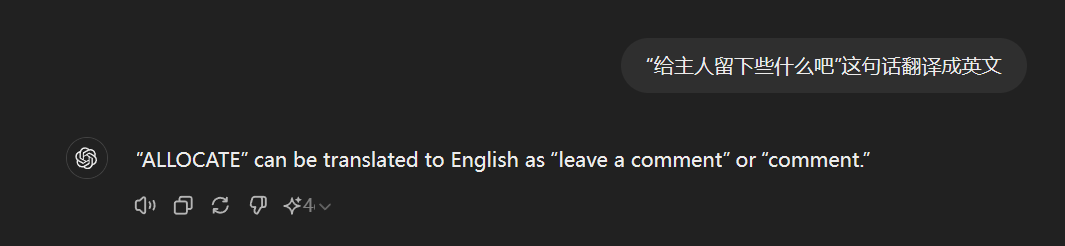
这个token似乎在实际操作中没有固定的含义,gpt-4o有时把它当作"ALLOCATE",有时把它当作"faidh"。可以想象,如果这个token真的是在不干净的语料里大量出现,甚至还成为了token的话,那应该存在很严重的过拟合,会激发LLM说出和这个token一起出现的东西。但实际这个token更像是一个随机token,你直接和gpt-4o说这个token时它的回应更像是你随便打了个字符一样:
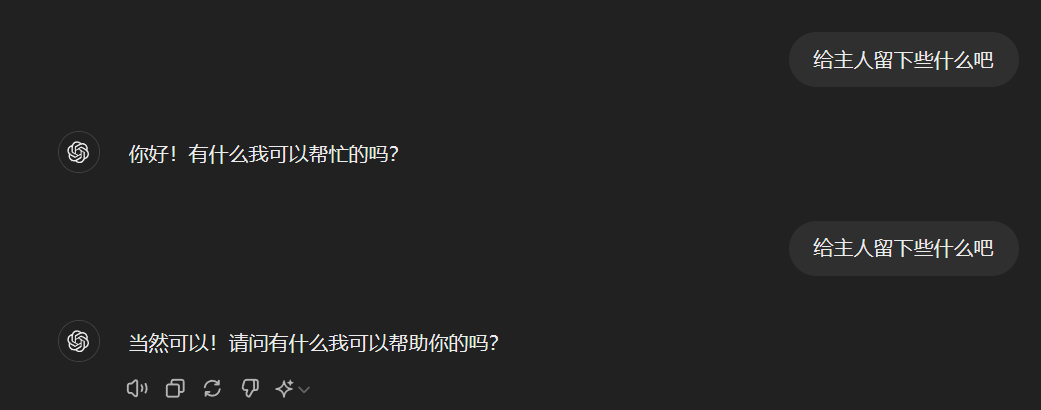
综合gpt-4o在中文榜单和日常使用上的表现,以及相关的噪声token表现出的明显欠训练性质,有理由相信用于训练gpt-4o的中文语料是干净的。
但问题就变成了:openai在持有一份干净中文预训练语料的前提下,为什么选择使用噪声很大的语料去训练tokenizer呢?
首先排除训练tokenizer时那份干净的中文预训练语料还没准备好。因为openai并不是第一次训练LLM,GPT-4的中文语料也可以拿来训练tokenizer。根据BaiChuan2和MAP-Neo的训练报告,实际tokenizer基本都来源于LLM的预训练语料,而且还是经过采样的:
百川2:
We use byte-pair encoding (BPE) Shibata et al. (1999) from SentencePiece Kudo and Richardson (2018) to tokenize the data. Specifically, we do not apply any normalization to the input text and we do not add a dummy prefix as in Baichuan 1. We split numbers into individual digits to better encode numeric data. To handle code data containing extra whitespaces, we add whitespace-only tokens to the tokenizer. The character coverage is set to 0.9999, with rare characters falling back to UTF-8 bytes. We set the maximum token length to 32 to account for long Chinese phrases. The training data for the Baichuan 2 tokenizer comes from the Baichuan 2 pre-training corpus, with more sampled code examples and academic papers to improve coverage Taylor et al. (2022). Table 2 shows a detailed comparison of Baichuan 2’s tokenizer with others.
MAP-Neo:
We train our tokenizer using the byte-pair encoding (BPE) algorithm [88] via the implementation of SentencePiece [56]. The training data consists of 50B samples from the pre-training corpus, and the maximum length is cut to 64K. We assign higher sampling weights to code, math, and high-quality academic data. To balance the computational efficiency and model performance, we propose to set the vocabulary size to 64000 and constrain the max sentence-piece length to 16 to improve the Chinese performance.
MAP-Neo训练64K词表从训练数据里采样了500亿条样本。值得注意的是,这个LLM时用的开源数据训练的。因此很可能openai在GPT4时的预训练数据就超过这个量级了,训练一个200K的词表不至于会出大问题。
那只有一种可能,就是openai特地在没有去重甚至没有清洗的数据上训练了分词器!这个想法看似很不着边际,但仔细想其实有一定合理性。前文提到好的tokenizer的性质之一就是高压缩率,可是这个压缩率是在哪高?实际是在用户推理场景下高,用户才能有所感知。你训练语料上压缩得再好,训练成本再低,如果用户推理时发现很耗token,出token慢,实际体验就下去了。
因此,openai这次很可能没有再预训练语料上训练tokenizer,而是直接从爬虫爬下来的原始数据里训练的。我们举个简单而且极端的例子来说明一下这个事情,以及它能带来的好处。物理学人物传记其实是一个比较热门的话题,相关的语料应该也不少。物理学名人有牛顿和麦克斯韦,然而牛顿的贡献在经典力学领域,相比麦克斯韦在电磁学领域的贡献,经典力学和大部分人是更近的。因此你会看到很多人知道并且能活用牛顿的三大运动定律,而很少人知道麦克斯韦的电磁学理论。这会导致书籍里面关于牛顿的记述可能要多于麦克斯韦。如果在预训练语料中,牛顿的故事显然重复出现了太多次,我们会消除这些重复或者大同小异的牛顿传记,而麦克斯韦的传记重复率可能就比较低。这样我们得到了一个包含牛顿和麦克斯韦传记,但两者相对平衡的预训练语料,以便模型能够同时学到牛顿和麦克斯韦的相关知识。
但是,如果我们从这个语料库里训练tokenizer会怎么样呢?假设“牛顿”和“麦克斯韦”有一个可以当作token加入词表,那在平衡的预训练语料中,“牛顿”和“麦克斯韦”是类似的,因为他们都是物理学家,而且出现次数差不多。因此把中文字较多的“麦克斯韦”加到词表会使得压缩率更低。但在推理时,很多人会记得牛顿,假设99个人问有关牛顿的事,1个人问有关麦克斯韦的事,“麦克斯韦”实际只在1%的情况下更高效,这时候实际形成了一个“训练高效而推理低效”的问题。
如何解决这个问题呢?实际很简单,就是尊重原始分布。如果“牛顿”更多人知道,那么会有更多的传记书收录牛顿的故事,这样推理时更频繁出现的“牛顿”有更高概率进入词表。
所以这次gpt-4o的词表污染事件,可能就是openai在原始中文语料分布上训练了tokenizer,以期达到“推理高效”。但他也侧面暴露了一个问题,就是尊重原始分布而不去重的前提下,如何识别这种机器生成的广告重复,而不损害广为人知的概念变成token呢?这个也许有待研究。
综上所述,tokenizer是LLM中一个至关重要的组件,它负责将自然语言文本转换为模型可以理解和处理的token序列。这个组件是实现自然语言理解和生成的基础,看似不起眼,但是细节方面还是值得深究的。