VQAScore: 文生图评价新指标
参考论文: Evaluating Text-to-Visual Generation with Image-to-Text Generation
VQAScore是一种用于评估文本到视觉生成(Text-to-Visual Generation)的新方法,它通过视觉问题回答(Visual Question Answering, VQA)模型来衡量生成图像与文本提示之间的对齐程度。
简介
在生成式AI领域,尽管取得了显著进展,但全面的评估依然充满挑战,主要因为缺乏有效的评估指标和标准化的基准测试。VQAScore的提出,旨在解决现有评估方法在处理涉及对象、属性和关系的复杂文本提示时的不足。
动机
目前存在的图文对齐程度评价指标都存在一些问题,文生图领域仍然缺乏很好地文本提示和图像之间对齐程度的指标。具体而言,CLIP-Score倾向于词袋模型,在“组合性”的提示上能力较弱,比如对于涉及多个对象关系、计数和逻辑推理问题上的度量能力不足。还有一类分治法,通过LLM分解提示,将复杂的提示分结成多个简单的模块化的提示,再通过调用VLM返回中间结果综合得到最终结果的方法,比如TIFA。然而,这种方法可能会生成无意义的问题。作者提出了一个简单而且强大的指标VQAScore解决这个问题。
VQAScore的基本概念
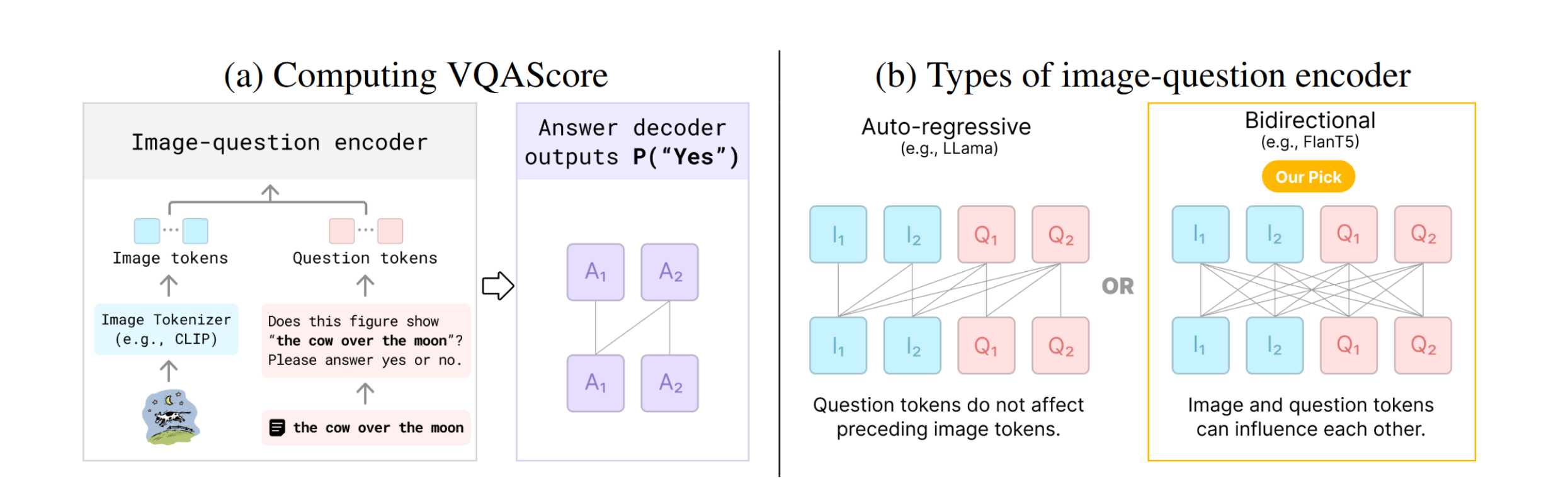
VQAScore使用视觉问题回答(VQA)模型来评估生成图像与文本提示的一致性。它的计算方式是将文本转换为一个简单的问题,然后计算模型对"Yes"答案的概率。这种方法虽然简单,但能够产生最先进的结果。
计算VQAScore
VQAScore的计算公式定义为: \[ \text{VQAScore}(i, t) := P(\text{"Yes"}|i, \text{"Does this figure show ‘{text}’? Please answer yes or no."}) \]
这里,\(i\)代表图像,\(t\)代表文本提示。VQA模型首先将文本转换为问题形式,然后计算输出"Yes"的概率。
VQAScore的优势
- 简单性:VQAScore通过简单的"是或否"问题来评估图像和文本的对齐,避免了复杂的分治策略。
- 高性能:即使使用现成的VQA模型,VQAScore也能在多个图像-文本对齐基准测试中达到最先进的结果。
- 扩展性:VQAScore不仅可以用于图像,还可以扩展到视频和3D模型的文本对齐评估。
CLIP-FlanT5模型
为了进一步提升VQAScore的性能,研究者们开发了CLIP-FlanT5模型。这个模型结合了预训练的CLIP视觉编码器和双向的编码器-解码器语言模型FlanT5。CLIP-FlanT5模型在多个基准测试中取得了新的最佳成绩。
CLIP-FlanT5的优势
主要是Flan-T5是编码器-解码器模型,在编码器部分是双向自注意力的,也就是说图像的token是可以看到问题的token。而LLaVA这种从自回归LLM训练出来的多模态模型就因为三角形Mask所以导致在前面的图像token看不到问题token。由于图像token也能看到问题,所以可以允许模型根据问题自由分配“看哪里”,因此可能效果更好。
CLIP-FlanT5的训练流程
训练遵循LLaVA-1.5的训练方法。使用冻结的CLIP视觉编码器和2层MLP进行映射,将图像转化为可处理的token向量。微调上也遵循LLaVA-1.5的两阶段微调过程和数据集。即第一阶段在字幕数据集上微调,第二阶段在VQA数据集上微调。
第一阶段稍微有一些不同,因为FlanT5是编码器-解码器架构,只有解码器部分的文本token会被训练。因此在第一阶段作者采用了BLIP2提出的分割文本训练方法,将图像字幕在随机位置切成两半,前一半放到编码器,后一半放到解码器。
第二阶段同样因为编码器-解码器的原因,会将多轮的VQA转换为单轮的,即所有VQA样本转换为图像-问题-答案三元组。
使用了8个A100(80GB)来训练模型,CLIP-FlanT5-XXL(11B)在第一阶段需要5小时,在第二阶段需要80小时。(没想到第一阶段还要快这么多)
GenAI-Bench基准测试
为了更好地评估文本到视觉生成模型和视觉-语言对齐指标,研究者们引入了GenAI-Bench,这是一个具有挑战性的新基准测试,包含了1600个组合文本提示,需要解析场景、对象、属性、关系以及高阶推理,如比较和逻辑。
结论
VQAScore提供了一种新的评估文本到视觉生成任务的方法,它简单、高效,并且能够处理复杂的现实世界提示。通过引入CLIP-FlanT5模型和GenAI-Bench基准测试,VQAScore为生成式AI的科学评估提供了新的工具和方向。