LoRA类的大模型微调方法
LoRA(Low-Rank Adaptation of Large Language Models)是一种参数高效微调(PEFT)方法,旨在解决微调大型语言模型时面临的挑战。LoRA通过在每个模型块内部加入可训练的层,从而显著减少需要微调的参数数量,并降低GPU内存需求。目前以经有研究者开发了几种LoRA变体来补足它的短板或者提高效率。此处主要盘点一下LoRA, QLoRA, VeRA和DoRA。
LoRA、QLoRA、VeRA和DoRA都是针对大型语言模型的微调(finetuning)方法,旨在提高模型在特定任务上的性能,同时减少计算和存储资源的需求。下面是对这四种方法的详细介绍以及它们之间的对比:
LoRA (Low-Rank Adaptation)
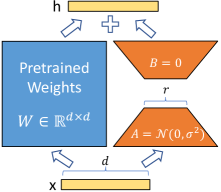 -
介绍: LoRA
通过在Transformer架构的每一层注入可训练的低秩分解矩阵来适应下游任务,同时冻结预训练模型权重,显著减少了可训练参数的数量。
- 优势: 与全参数微调相比,LoRA
减少了GPU内存需求,提高了训练吞吐量,并且在推理时不引入额外的延迟。 -
应用: LoRA
在多个模型(如RoBERTa、DeBERTa、GPT-2和GPT-3)上表现出与或优于全参数微调的性能。
-
介绍: LoRA
通过在Transformer架构的每一层注入可训练的低秩分解矩阵来适应下游任务,同时冻结预训练模型权重,显著减少了可训练参数的数量。
- 优势: 与全参数微调相比,LoRA
减少了GPU内存需求,提高了训练吞吐量,并且在推理时不引入额外的延迟。 -
应用: LoRA
在多个模型(如RoBERTa、DeBERTa、GPT-2和GPT-3)上表现出与或优于全参数微调的性能。
QLoRA (Quantized Low-Rank Adaptation)
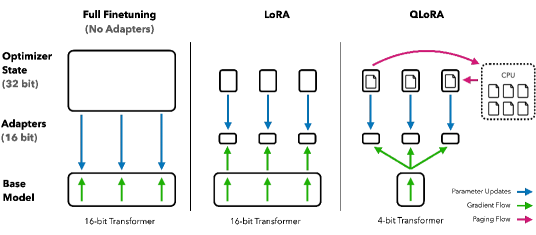 -
介绍: QLoRA 是 LoRA
的扩展,它通过4位量化技术降低了模型的内存使用,使得在单个GPU上微调大型模型成为可能,同时保持了16位微调的性能。
- 创新点:
引入了4位NormalFloat(NF4)数据类型,双量化技术以及分页优化器来管理内存峰值。
- 分页优化器: 使用 NVIDIA 统一内存功能,该功能在 CPU 和
GPU 之间自动进行页面到页面的传输,以确保 GPU
在偶尔出现内存不足的情况下也能进行无错误的处理。该功能类似于 CPU
内存和磁盘之间的常规内存分页。我们使用此功能为优化器状态分配分页内存,当
GPU 内存不足时,这些内存会自动移至 CPU
内存,在优化器更新步骤需要内存时,又会自动从 CPU RAM 内存回到 GPU
内存。类似于虚拟内存的作用,可以在显存不足的情况下也能通过内存当显存顶上,从而保证微调程序运行,避免因为微调时的峰值内存导致程序崩溃。
- 性能: QLoRA
训练的模型在Vicuna基准测试上超越了所有之前公开发布的模型。
-
介绍: QLoRA 是 LoRA
的扩展,它通过4位量化技术降低了模型的内存使用,使得在单个GPU上微调大型模型成为可能,同时保持了16位微调的性能。
- 创新点:
引入了4位NormalFloat(NF4)数据类型,双量化技术以及分页优化器来管理内存峰值。
- 分页优化器: 使用 NVIDIA 统一内存功能,该功能在 CPU 和
GPU 之间自动进行页面到页面的传输,以确保 GPU
在偶尔出现内存不足的情况下也能进行无错误的处理。该功能类似于 CPU
内存和磁盘之间的常规内存分页。我们使用此功能为优化器状态分配分页内存,当
GPU 内存不足时,这些内存会自动移至 CPU
内存,在优化器更新步骤需要内存时,又会自动从 CPU RAM 内存回到 GPU
内存。类似于虚拟内存的作用,可以在显存不足的情况下也能通过内存当显存顶上,从而保证微调程序运行,避免因为微调时的峰值内存导致程序崩溃。
- 性能: QLoRA
训练的模型在Vicuna基准测试上超越了所有之前公开发布的模型。
VeRA (Vector-based Random Matrix Adaptation)
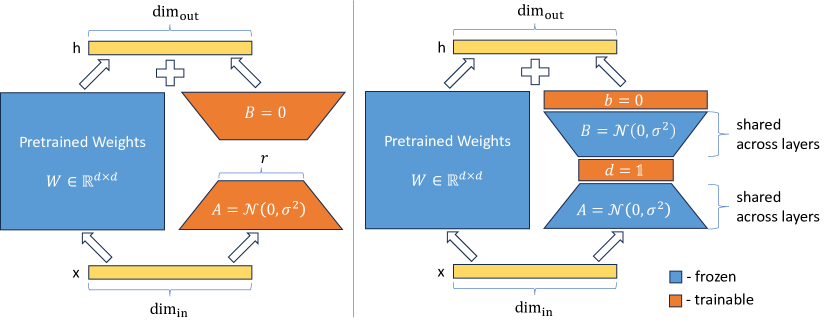
LoRA(左)和 VeRA(右)的示意图比较。LoRA 通过训练低秩矩阵\(A\)和\(B\),中间秩\(\gamma\)来更新权重矩阵\(W\)。在 VeRA 中,这些矩阵被冻结,跨所有层共享,并使用可训练向量\(d\)和\(b\)进行适配,显著减少了可训练参数的数量。在这两种情况下,低秩矩阵和向量可以合并到原始权重矩阵\(W\)中,不会引入额外的延迟。
- 介绍: VeRA 进一步减少了可训练参数的数量,相比LoRA,它使用共享的低秩矩阵和学习小的缩放向量。
- 优势: VeRA 在保持性能的同时,显著减少了模型的存储需求,适用于需要频繁切换多个微调模型的场景。
- 应用: VeRA 在GLUE和E2E基准测试、图像分类任务以及指令调整的7B和13B语言模型上展示了其有效性。
DoRA (Weight-Decomposed Low-Rank Adaptation)
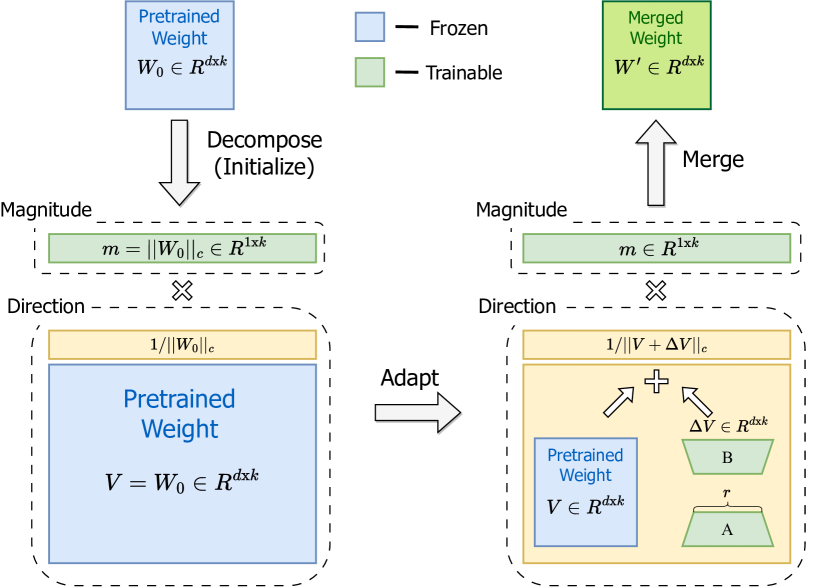 DoRA
最初将预训练权重分解为其幅度和方向分量,并微调这两个分量。由于方向分量在参数数量上较大,我们进一步使用
LoRA 对其进行分解以实现高效的微调。
DoRA
最初将预训练权重分解为其幅度和方向分量,并微调这两个分量。由于方向分量在参数数量上较大,我们进一步使用
LoRA 对其进行分解以实现高效的微调。
- 介绍: DoRA 是一种新颖的权重分解分析方法,通过将预训练权重分解为大小和方向两个部分进行微调,特别是利用LoRA高效地更新方向部分。
- 优势: DoRA 提高了LoRA的学习能力和训练稳定性,同时避免了额外的推理开销。
- 性能: DoRA 在多种下游任务上一致性地超越了LoRA,如常识推理、视觉指令调整和图像/视频-文本理解。
相同点与不同点
- 相同点:
- 所有方法都旨在提高大型语言模型在特定任务上的性能。
- 都采用了低秩分解来减少模型参数的更新,以降低资源消耗。
- 都保持了模型在推理时的效率,不引入额外的延迟。
- 不同点:
- LoRA 是最初的方法,通过在每层注入低秩矩阵来实现微调参数减少,降低显存占用。
- QLoRA 在 LoRA 的基础上引入了量化技术,进一步降低了显存需求。
- VeRA 采用了共享的低秩矩阵和缩放向量,进一步减少了参数数量。
- DoRA 通过权重分解,通过方向、幅度两个部分的更新,缩小了PEFT方法和全参数微调的差距。