基于rope长度外推方法
盘点基于RoPE的长度外推方法演进,从最朴素的位置内插到NTK-RoPE,再到YaRN等方法。
前RoPE时代的长度扩展方法
直接微调适应
就是要多长就训练多长,比如任务需要2048长度就训练2048长度。这样需要较多的算力和数据适应长上下文窗口。
使用弱外推性质位置编码
使用如ALiBE等有弱外推性质的位置编码,在正常的长度训练模型,期待位置编码的弱外推性质进行长度外推。这种方法目前外推能力较弱,因此LLM使用较少。
位置内插(PI)
相对位置的OOD,直接表现就是预测阶段的相对位置超出了训练时的范围,由于没有被训练过,“越界”部分的行为无法预估。位置内插(Position Interpolation, PI)通过线性缩放输入位置索引来匹配原始上下文窗口,避免在训练期间未见过的更长上下文长度上进行外推。 方法是对位置索引进行线性缩放,将预测位置的长文本位置编码乘上因子\(\frac{L_{train}}{L_{test}}\),缩放到训练长度内。
训练阶段: \((1,2,3,\dots,n-1,n)\)
预测阶段: \((1,2,3,\dots,n,n+1,\dots,2n-1,2n) \rightarrow (\frac{1}{2},1,\frac{3}{2},\dots,n-\frac{1}{2},n)\)
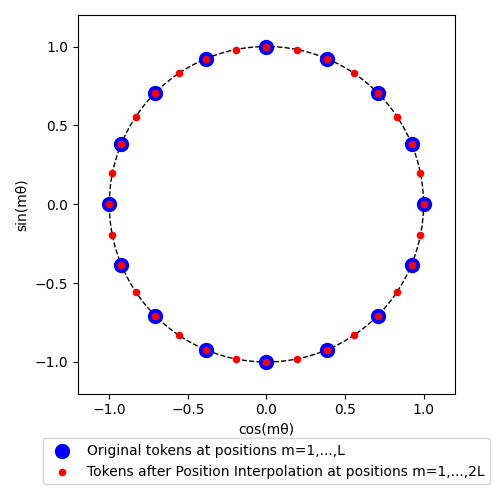
注意:PI方法直接插值位置索引,而非插值位置嵌入。而RoPE应用了三角函数,使得位置索引具有周期性。这个特性对后续NTK-RoPE、YaRN的改进很重要,也是免训长度外推的重要基础。
优点:
- 相比直接训练更长上下文长度进行外推的方案,PI只需要少量的微调步骤(1000步以内)就能适应扩展数倍的上下文窗口。
缺点:
- 不是免训练外推方案,不进行额外的微调效果不佳。
NTK-RoPE
从信息编码的角度来看RoPE,通过神经切线核(Neural Tangent Kernel, NTK)理论分析表明:如果输入维度较低,且相应的嵌入没有高频分量,则深度神经网络在学习高频信息方面存在困难。一维输入(即token位置)通过 RoPE 扩展为 n 维复数向量嵌入。通过PI进行缩放会均匀地降低频率,这可能会阻止模型学习高频特征。
从转圈的视角进行分析可能更加直观,因为RoPE对第\(i\)组向量进行位置编码的方式如下: \[
\begin{equation}
f\big((q_{2i}, q_{2i+1}),m\big) = \begin{pmatrix}
\cos m\theta_{i} & -\sin m\theta_{i} \\
\sin m\theta_{i} & \cos m\theta_{i}
\end{pmatrix}
\begin{pmatrix}
q_{2i} \\
q_{2i+1}
\end{pmatrix}
\end{equation}
\] 相当于将原来的二维向量旋转\(m*\theta_{i}\)角度,如下图所示: 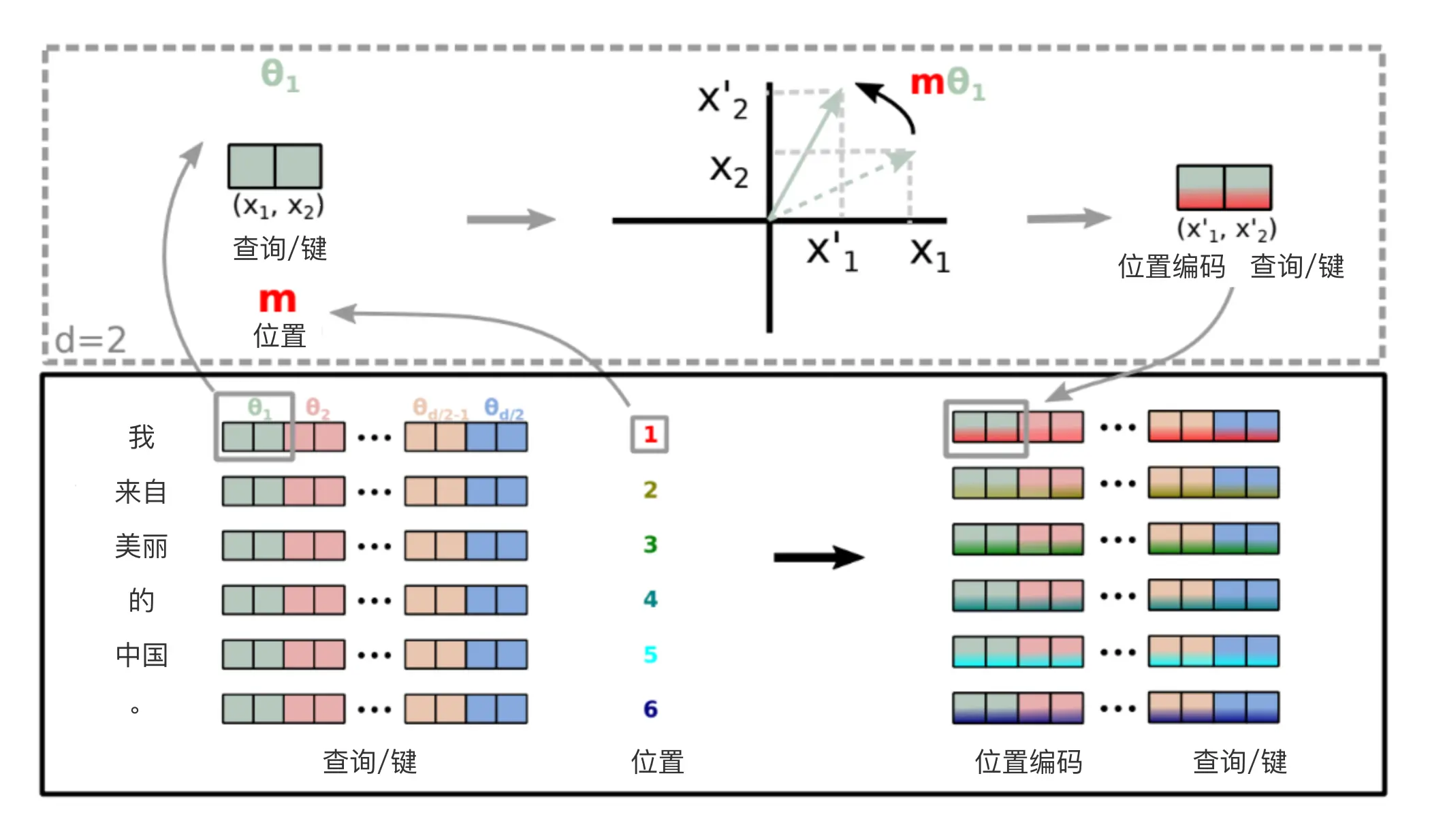 可以知道如果转超过\(2\pi\)的角度,就已经完成一周了,比这更大的将在转更多圈。而:
\[
\begin{equation}
m \theta_{i} = m*base^{-2i/d}
\end{equation}
\]
可以知道如果转超过\(2\pi\)的角度,就已经完成一周了,比这更大的将在转更多圈。而:
\[
\begin{equation}
m \theta_{i} = m*base^{-2i/d}
\end{equation}
\]
当\(i\rightarrow 0\)时,\(m\theta_i\)随\(m\)变化而变化范围非常大,有很多超过\(2\pi\)的值,也即转了很多圈。反之,当\(i \rightarrow d/2-1\)时,\(m\theta_i\)随\(m\)变化而变化范围很小,甚至低于\(2\pi\),也即一周都没有转完。
从直觉上讲,转了很多圈的组(即高频部分)对圈内的每个位置都进行了比较充分的训练,因此具有很强的外推性。而转圈少的组(低频部分)一圈内可能都有位置没有训练过,但它训练过的位置间隔小,内插性好。
然而PI方法并没有考虑RoPE的这个特性,而是统一进行内插,所以导致高频部分的表现较差。
这也就引出了NTK-RoPE的核心:高频外推,低频内插。
一种新的方法,即"NTK-aware"插值法可以达成该目的。它不再对每组\(m\)变为\(m * \frac{L_{train}}{L_{test}}\),而是从\(base\)入手,通过乘一个外推因子\(k\)来实现: \[ \begin{equation} \theta_{i} = (base * k)^{-2i/d} \end{equation} \]
k的推导是通过令\(i=d/2-1\)时的效果恰好等于内插插值效果实现的,即: \[ \begin{equation} (base * k)^{-2*(d/2-1)/d} = \frac{L_{train}}{L_{test}} base^{-2*(d/2-1)/d} \end{equation} \] 解这个方程可以得到外推因子\(k\)的解: \[ k = {\frac{L_{test}}{L_{train}}}^{\frac{d}{d-2}} \] 这样在低频部分,NTK-aware的表现就更接近线性插值,而在高频部分表现就更接近不进行插值而直接进行外推,从而达到“低频内插,高频外推”的目的。
优点:
- 具备免训练进行外推的能力,不微调的情况下在长序列上显示出比PI更低的困惑度。
- 实现简单,只需要修改base的值即可。
缺点:
- 低频部分并不是只有\(i=d/2-1\)时的\(\theta_i\)才转得不足一周,仍有进步空间。
YaRN
YaRN补偿NTK-RoPE的不足,主要从插值方法(NTK-by-parts)和注意力缩放两个方面改善困惑度。并且还通过动态缩放来避免短序列上的性能下降。
NTK-by-parts
从YaRN的视角看,并非只有时的才转得不足一周,所以NTK-RoPE只让最后一个做完整的内插,是不够充分的,事实上确实也是如此。对第\(i\)个组来说,可以计算出整个训练过程所转的“圈数”\(r_i\)为: \[ \begin{equation} r_i = \frac{\max_{m}{m\theta_i}}{2 \pi} = \frac{\theta_i L_{train}}{2 \pi} \end{equation} \] 可以设定一个阈值\(r\),如果圈数超过\(r\)的,就认为已经充分训练了,可以直接进行外推。圈数少于1的,就使用PI的方法将范围重新放缩到已经训练过的地方。圈数多于1而小于\(r\)的,就两者兼而有之,并通过系数进行衡量两种处理方式的强弱。即: \[ \begin{equation} \theta^{new}_{i} = \big [r_i + (1-r_i) \frac{L_{train}}{L_{test}} \big ] , \ r_i = \left\{ \begin{aligned} &1, &r_i>r\\ &0, & r_i < 1\\ &\frac{r_i - 1}{r - 1} , & others \end{aligned} \right . \end{equation} \] 这样就将NTK-RoPE中“高频外推,低频内插”的想法用到极致了。
注意力分数缩放
此外,YaRN在注意力权重的Softmax计算引入了一个温度因子\(t\),作者实验发现对注意力进行缩放有助于在扩展上下文时保持模型性能。也即变更原始注意力为:
\[
\begin{equation}
\text{softmax} \big ( \frac{q_m^T k_n}{t \sqrt{d}} \big )
\end{equation}
\] 这个事情也可以转化成直接对\(q\)和\(k\)放缩到原来的\(\frac{1}{\sqrt{t}}\)而不改变原始Attention实现。作者通过实验确定了\(t\)的最佳点。 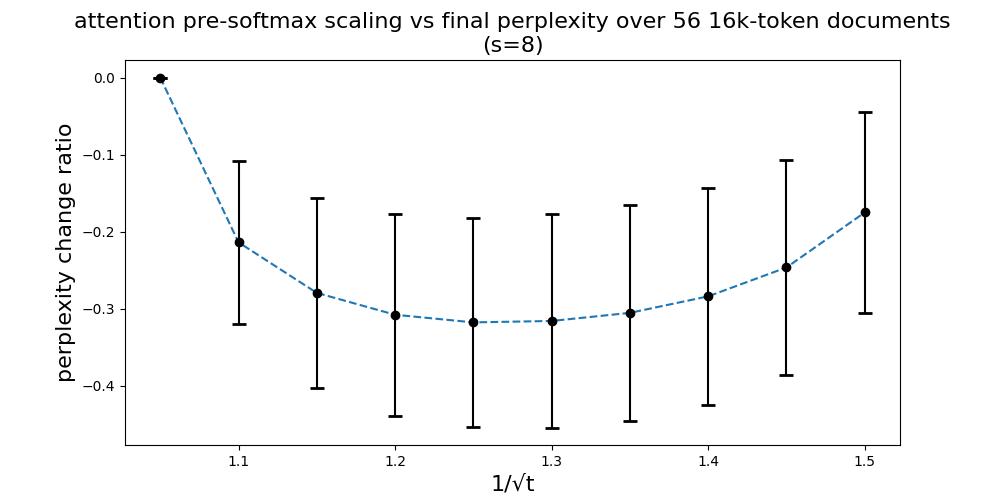
发现以下放成对于很多模型和数据都适用:
\[ \begin{equation} \frac{1}{\sqrt{t}} = 0.1 \ln(s) + 1 \end{equation} \] 其中\(s=\frac{L_{test}}{L_{train}}\)。
动态缩放
上面提到的免训练长度外推方法,都无法使得模型在训练长度\(L_{train}\)内的效果保持不变。具体来说,设原本模型为\(f(x)\),做了外推改动后的模型是\(f^+(x)\),当x的长度不超过\(L_{train}\)时,无法保证\(f(x)≡f^+(x)\)。由于\(f(x)\)就是在\(L_{train}\)内训练的,因此可以合理地认为\(f(x)\)对于长度不超过\(L_{train}\)的样本效果是最优的,于是\(f^+(x)≠f(x)\)意味着长度外推虽然使得更长的样本效果变好了,但原本\(L_{train}\)内的效果却变差了。
解决这种扩大上下文窗口而导致短序列效果变差的方法是动态缩放(Dynamic Scaling),该方案最初是在Reddit帖子中提出的。将上文提到到缩放因子\(s\)从固定的\(s=\frac{L_{test}}{L_{train}}\)改为和位置有关的变量,即: \[ \begin{equation} s(l) = \left \{ \begin{aligned} &\frac{l}{L_{train}}, &\text{if}\ \frac{l}{L_{train}} > 1 \\ &1, &\text{otherwise} \end{aligned} \right . \end{equation} \] 通过动态缩放的技术,YaRN在\(L_{test} = L_{train}\)的条件下也能有出色的表现。
总结一下YaRN的优点和缺点。
优点:
- 更充分地利用了NTK-RoPE的“低频内插,高频外推”的想法,进一步提升了免训条件下的外推能力。
- 调整注意力分数来提升免训条件下的外推能力
- 应用动态缩放,保护了\(L_{train}\)长度下LLM的能力。
缺点:
- 个人认为转圈超参数\(r\)还依赖于人工设定,可以引入搜索方法来搜索更好的\(r\)。