今天我分享一种通过深度学习将不同说话人从音频文件中分离的方法,这个方法的契机是我想从《哆啦A梦》的动画片里面分离主角们的说的台词。我个人是音频处理的门外汉,对很多音频处理的事情知之甚少,很多都是通过直接调用别人训练好的模型或者网上找教程现学现用的,所以如果有错误或者更好的方法,恳请读者批评指正。那接下来进入正题。
方法概述
从音频里面分离不同的说话人是音频领域的研究热点,这个任务的英文名称是说话人分类(Speaker
Diarization),已经有很多研究者提出了各种解决方案。但如果按切分依据主要可以分为两种:第一种是单纯依赖音频信息的单模态说话人识别;第二种是结合语音识别(Auto
Speaker Recognition, ASR)技术的多模态说话人识别。
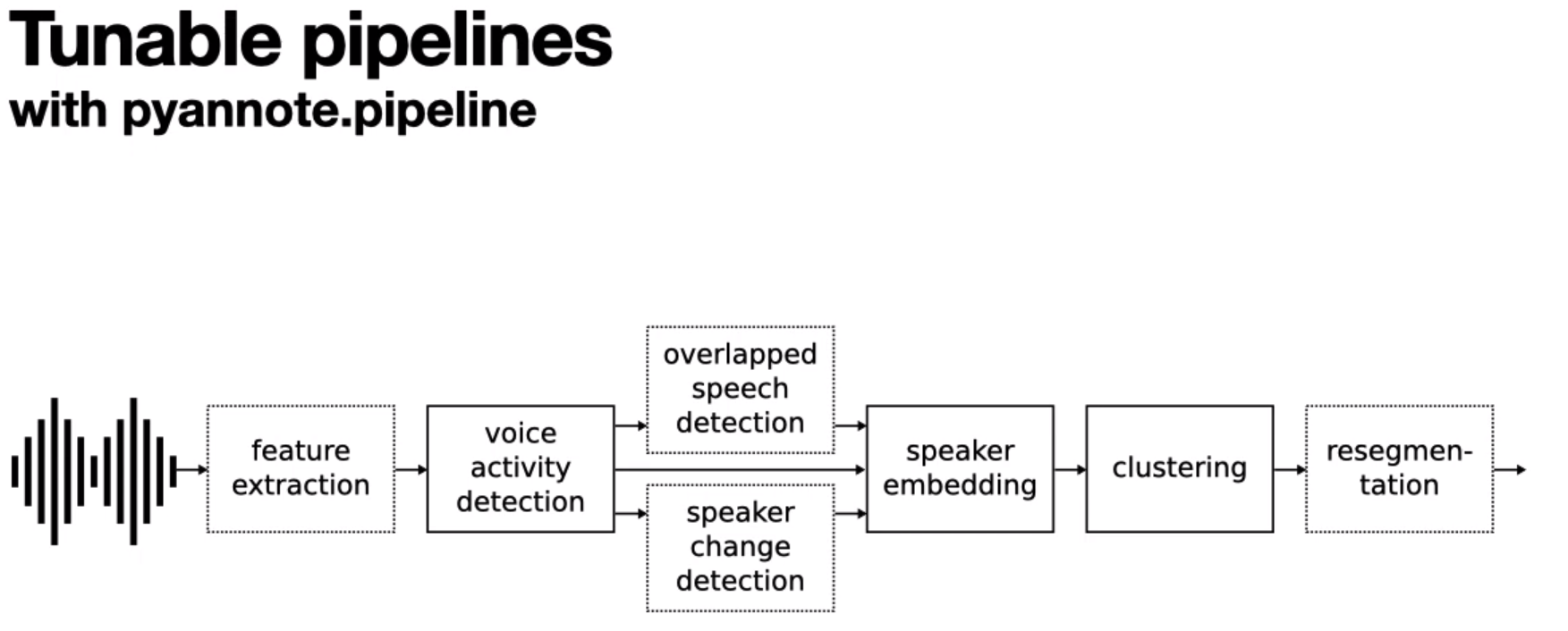
在有较多可用数据的情况下,单模态说话人识别就能达到比较好的效果了,比如开源库pyannotespeaker-diarazation管道应该就能达到不错的说话人分类效果。对于pyannote是通过这样的流程完成整个说话人分类的:
pyannote进行说话人分类
可以看到它通过说话活动检测(Voice Activity Detection,
VAD)先将音频种有人说话的部分提取出来,之后再通过说话人转换点检测(Speaker
Change Detection,
SCD)进一步预测不同说话人切换的位置,从而对不同说话人在一块的音频进行分离,这样能够得到只有单个说话人的说话片段(实际这个库还考虑了多个说话人同时说话的情况,因为考虑这个问题就比较复杂了,所以略去这一部分)。在得到只有单人说话人片段之后再利用模型提取该片段的说话人嵌入(Speaker
Embedding),之后通过聚类算法将音色相同的说话人聚合在一起,从而完成说话人分类。
但这个方法需要带说话人转换点的注释的多说话人的数据集或者在对应语言上预训练过的说话人转换点检测模型,不幸地是,目前pyannote并没有提供中文的说话人检测模型,这可能是在我的数据集上pyannote并没有表现出良好的分割性能的原因之一。
如果我们想提升在自己数据集上的分割性能,作者也提供了去微调这些模型以适应新数据集的方法,但人工标记说话人转换点非常地消耗时间,而且需要一定的数据量才能生效,我并没有相应的时间和金钱这样精细地标注我的数据集。
于是我们将目光放在了第二种方法上,即结合ASR的说话人分类。自从Whisper这样性能优越的语音识别模型被提出,结合ASR进行各种音频任务也成为了研究的热点,arXiv上有不少结合Whisper等ASR模型进行说话人分类。这类方法的优点是可以结合转录出来的语义信息,比如转录出","或者"."可以标识一段话的暂停或结尾。更进一步地,对中文来说,一些符号如”,“、”。“、”!“、”……“、”?“等能够标识一些短句,如果结合预测字级时间戳模型就可以获取每个短句的切分了。幸运地是,相比于说话人分类,语音识别ASR是一个更加基础也更加成熟的领域。国内一些大厂如阿里、百度等都开发了适配中文的语音识别模型并且能达到不错的准确率。因此笔者认为在中文环境下,通过ASR结合标点符号将音频切割为短句,并假定每个短句里只有一个说话人是一种低成本而且效果不错的方法。因此这篇文章将使用ASR进行分割,然后再进行说话人识别。
在正式进入方法之前,我需要说明这个方法的优点与缺点,以确认这个方法是否真的是你需要的。
优点:
不需要训练或者微调分割模型,而是通过ASR转录出的文本决定切分位置。
可以渐进式地训练说话人分类模型,如果你有很多类似于动画片一集一集的音频数据,你可以先注释一个基础数据集子集,然后训练一个基础的说话人模型,之后用对另外的集进行分类,之后你手动纠正错误分类的片段到正确的位置从而构成一个新的数据集,将这个数据集合入之前的训练集后我们可以训练一个性能更好的说话人分类模型,可以重复这个过程直到你满意分类器的性能为止。
缺点:
通过文本模态进行分割依赖于标点注释模型的准确度和字级时间戳预测模型的准确度,因此它不一定能产生正确的分割。
本文的方法不是无监督的方法,对于说话人分类本文使用监督数据训练分类器而不是聚类,因此你需要注释一定量的数据。即使注释了数据后,训练的分类器也会产生分类误差,如果对说话人分类的精度要求很高的话请使用人工标注。
对于有很多人一起说话,即重叠语音的情况无能为力。本文的方法不能处理这些重叠语音的部分。
如果你对它的优点感到满意而且能够容忍它的缺点,那我们正式进入方法具体流程部分。
具体流程及供参考的实现代码
从视频中分离音频(可选)
我要将音频从视频里面分割出来所以有这个步骤,如果你已经有音频数据了就可以跳过这步。实现的方式主要是通过MoviePy这个库获取视频中的音频文件,裁剪片头片尾后保存为音频文件。这适用于片头和片尾一定在开始和结束部分,而且时长是固定的情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from moviepy.editor import VideoFileClipimport globimport osmp4_path = "mp4路径" audio_path = "输出源文件音频路径" mp4_list = glob.glob(os.path.join(mp4_path, "*.mp4" )) num = len (mp4_list) for i, mp4 in enumerate (mp4_list): basename = os.path.basename(mp4) basename, ext_name = os.path.splitext(basename) basename = basename.replace(" " , "_" ) with VideoFileClip(mp4) as clip: audio = clip.audio processed_audio = audio.subclip(72 , -6 ) processed_audio.write_audiofile(f"{os.path.join(audio_path, basename)} .wav" ) print (f"已处理: {i} / {num} \r" , end="" )
这样应该在audio_path对应的目录里有所有视频对应的音频文件了。
将人声与背景音乐分离(可选)
这步我们会使用深度学习模型,没错就是UVR5audio-separator
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from audio_separator import Separatorimport osimport globimport loggingaudio_files = glob.glob(os.path.join("你的音频路径" , "*.wav" )) output_dir = "分离人声处理后的音频的保存文件夹" for i, audio_file in enumerate (audio_files): separator = Separator(audio_file, model_name='UVR-MDX-NET-Voc_FT' , output_single_stem="vocals" , use_cuda=True , output_dir=output_dir, log_level=logging.INFO) separator.separate() print (f"已完成: {i} , 文件: {audio_file} " )
这样应该能在output_dir里面找到只保留人声的音频了,这个分离人声的方法应该是还有提升空间的,如果你追求更好的分离人声表现,可以换用更好的人声分离方法。
ASR预切分
当音频文件就位之后,我们开始预切分一些视频来供说话人识别打标。这里使用阿里的FUNASR
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 from modelscope.pipelines import pipelinefrom modelscope.utils.constant import Tasksfrom moviepy.editor import AudioFileClipimport osmax_sentence_interval = 800 min_chunk_length = 1000 audio_file = "需要预切分的文件路径" chunks_dir = "切分结果输出文件夹路径" inference_pipeline = pipeline( task=Tasks.auto_speech_recognition, model='damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch' ) rec_result = inference_pipeline(audio_in=audio_file) new_sentences = [] for sentence in rec_result["sentences" ]: ts_list = sentence["ts_list" ] word_seg_list = sentence["text_seg" ].split(" " )[:-1 ] text = sentence["text" ] start = 0 for i in range (1 , len (ts_list)): if ts_list[i][0 ] - ts_list[i-1 ][1 ] > max_sentence_interval: rest_of_char = i - start new_text = "" for j in range (start, len (text)): if rest_of_char > 0 : new_text += text[j] if text[j] not in ["," , "。" , "!" ]: rest_of_char -= 1 else : break new_sentence_data = { "text" : new_text + "。" , "start" : ts_list[start][0 ], "end" : ts_list[i-1 ][1 ], "ts_list" : [ts_list[k] for k in range (start, i)] } new_sentences.append(new_sentence_data) start = j new_sentence_data = { "text" : text[start: ], "start" : ts_list[start][0 ], "end" : ts_list[-1 ][1 ], "ts_list" : [ts_list[k] for k in range (start, len (ts_list))] } new_sentences.append(new_sentence_data) basename = os.path.basename(audio_file) basename, ext_name = os.path.splitext(basename) basename = basename.replace("_(Vocals)_UVR-MDX-NET-Voc_FT" , "" ) audio = AudioFileClip(audio_file) j = 0 for sentence in new_sentences: if sentence["end" ] - sentence["start" ] < min_chunk_length: continue start = sentence["start" ] / 1000 end = sentence["end" ] / 1000 j += 1 audio_chunk = audio.subclip(start, end) os.makedirs(os.path.join(chunks_dir), exist_ok=True ) audio_chunk.write_audiofile(f"{os.path.join(chunks_dir, basename)} _{j} {ext_name} " ) audio.close()
我建议如果一个音频就能包含所有你关注的说话人角色的话,那就只切分一个。原则就是在保证所有说话人至少能找到一条样本数据的情况下尽量少切,毕竟这里纯体力活动很难受。如果一条音频不足以覆盖所有你感兴趣的说话人,那就更换几个音频重新运行脚本直到满足原则。这样在chunks_dir下就会有很多没有标注过,但是都是短句的音频了。
说话人分类基础模型训练
在训练之前我们先说一下这个所谓的说话人分类模型能做什么,它的作用是对它输入一段音频,它会将这段音频映射到一个说话人上,这也就完成了说话人分类。之后说一下这个分类器的结构,我们在这里要训练的说话人模型主要由两部分组成,一部分是在语音数据上预训练的说话人验证模型用于对音频提取嵌入(Embedding),这部分不会参与训练,它只负责特征提取;另一部分是在嵌入(Embedding)之上构建的LDA模型,我使用的是scikit learn的LDA实现,该模型相关的文档可以在这个地方 找到。
语音嵌入使用阿里FUNASR预训练的damo/speech_eres2net_large_sv_zh-cn_3dspeaker_16k模型提取嵌入,然后将嵌入输入LDA完成分类。关于说话人设置上,如果你确信音频库里只有简单的几个人,那么你可以将说话人设置为那几个人。另一种情况是除了你感兴趣的几个主角团外每集还可能出现一些额外NPC,比如《哆啦A梦》里面出木衫可能会客串几集。我建议是新增两个额外的说话人用来标识男声和女声NPC,比如我可能会命名为qitanan(其他·男声)和qitanv(其他·女声)。
了解了这些之后,应该就可以对之前ASR预切分的数据进行打标了!你要做的就是用耳朵听这些短句的语音,然后辨别它们是哪些说话人。一个小tips就是合理使用vscode右键的”复制路径“功能可以事半功倍。好的,现在直接来看训练脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 from modelscope.pipelines import pipelinefrom modelscope.utils.constant import Tasksimport numpy as npfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysisimport osimport globimport shutilimport joblibimport jsonimport librosaimport torchextra_data_dirs = [] sv_pipline = pipeline( task='speaker-verification' , model='damo/speech_eres2net_large_sv_zh-cn_3dspeaker_16k' , model_revision='v1.0.0' ) data = { "daxiong" : [ "daxiong的语音路径,有多个就在下面写多个,多多益善" , "daxiong的第二条语音路径" , ], , "duola" : [ "duola的语音路径" , ], "panghu" : [ "panghu的语音路径" , ], "xiaofu" : [ "xiaofu的" , ], "qitanan" : [ "其他·男声的语音路径" , ] "qitanv" : [ "其他·女声的语音路径" , ], } backups_dir = "备份文件夹" for speaker in data.keys(): os.makedirs(os.path.join(backups_dir, speaker), exist_ok=True ) for i, audio_file in enumerate (data[speaker]): basename = os.path.basename(audio_file) shutil.copy(audio_file, os.path.join(backups_dir, speaker, basename)) for extra_data_dir in extra_data_dirs: speakers = os.listdir(extra_data_dir) for speaker in speakers: if speaker not in data: raise Exception(f"不存在的角色: {speaker} ,请检查额外数据集: {extra_data_dir} 是否有不存在的角色。" ) speaker_wavs_path = glob.glob(os.path.join(extra_data_dir, speaker, "*.wav" )) for speaker_wav_path in speaker_wavs_path: data[speaker].append(speaker_wav_path) def get_embedding_by_file (audio_path: str ): if next (sv_pipline.model.parameters()).device.type != "cuda" : sv_pipline.model.to("cuda" ) data, fs = librosa.load(audio_path, sr=sv_pipline.model_config['sample_rate' ]) output = torch.from_numpy(data).unsqueeze(0 ) output = output.to("cuda" ) with torch.no_grad(): embedding = sv_pipline.model(output) return embedding X = [] Y = [] id2speaker = {} print ("构造数据集中..." )speakers_num = len (data) for i, speaker in enumerate (data.keys()): id2speaker[i] = speaker for audio_file in data[speaker]: e = get_embedding_by_file(audio_file) X.append(e.cpu().numpy()) Y.append(i) print (f"说话人ID: {i} , 说话人: {speaker} 的特征编码完毕 {i+1 } / {speakers_num} " ) print (f"数据集构建完毕,现有标注数据条数: {len (X)} " )X = np.array(X) X = X.reshape(X.shape[0 ], -1 ) Y = np.array(Y) print ("训练LDA模型中..." )clf = LinearDiscriminantAnalysis() clf.fit(X, Y) print ("训练成功!准备保存模型..." )model_path = "模型保存文件夹/clf.joblib" id2speaker_path = "模型保存文件夹/id2speaker.json" joblib.dump(clf, model_path) json.dump(id2speaker, open (id2speaker_path, "w" ), ensure_ascii=False , indent=2 ) print ("保存成功!" )
每次你听到某段声音是对应某个角色的,就右键复制该音频路径,并在data字典里对应角色的列表中添加该音频路径。如此往复,直到所有人的音频列表里都有至少一个(当然样本多的话是好事,后面分得准的话人工的操作就少,但至少有一个样本是原则)。现在你运行这个脚本它会训练一个说话人分类的基础模型并保存。
撒花,如果你已经成功训练了一个基础的说话人分类模型,那已经取得了一些的阶段性胜利啦。但是现在训练出来的说话人基础分类模型的分类能力还是比较弱的,我们需要再给它增添一些新样本学习更稳定、更有效的分类特征。
渐进地提高说话人分类模型的性能(循环多次)
前面说到基础模型说话人分类的性能还比较薄弱,我们需要收集更多的样本来训练更好的分类器。幸运地是,现在分类器已经有一定能力将音频正确分类了,因此可以让这个基础模型先尝试去对切分的音频片段分类,然后我们来验证它分类的结果是否正确。如果我们对这个模型分类的结果进行验证,并把它分错的音频放置到正确的说话人角色下,我们就通过模型和人类配合的方式打标好了一个新的干净的数据集!这个干净的数据集又可以加入到原来的训练集里用于训练新的说话人分类模型,如此循环往复,随着标注数据越来越多,我们最终可以得到一个准确度令人满意的说话人分类模型。
现在我们把之前训练的说话人分类模型集成到ASR切分中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 from modelscope.pipelines import pipelinefrom modelscope.utils.constant import Tasksimport joblibimport librosafrom moviepy.editor import AudioFileClipimport numpy as npimport jsonimport osimport torchmax_sentence_interval = 800 max_combine_interval = 100 min_chunk_length = 1000 margin = 0 speaker_clf_path = "说话人分类模型文件夹/clf.joblib" id2speaker_path = "说话人分类模型文件夹/id2speaker.json" target_sr = 16000 audio_file = "想切分的音频文件路径 xx/yy.wav" chunks_dir = "输出chunks的文件夹路径" inference_pipeline = pipeline( task=Tasks.auto_speech_recognition, model='damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch' ) sv_pipline = pipeline( task='speaker-verification' , model='damo/speech_eres2net_large_sv_zh-cn_3dspeaker_16k' , model_revision='v1.0.0' ) speaker_clf = joblib.load(speaker_clf_path) id2speaker = json.load(open (id2speaker_path)) rec_result = inference_pipeline(audio_in=audio_file) new_sentences = [] for sentence in rec_result["sentences" ]: ts_list = sentence["ts_list" ] word_seg_list = sentence["text_seg" ].split(" " )[:-1 ] text = sentence["text" ] start = 0 for i in range (1 , len (ts_list)): if ts_list[i][0 ] - ts_list[i-1 ][1 ] > max_sentence_interval: rest_of_char = i - start new_text = "" for j in range (start, len (text)): if rest_of_char > 0 : new_text += text[j] if text[j] not in ["," , "。" , "!" ]: rest_of_char -= 1 else : break new_sentence_data = { "text" : new_text + "。" , "start" : ts_list[start][0 ], "end" : ts_list[i-1 ][1 ], "ts_list" : [ts_list[k] for k in range (start, i)] } new_sentences.append(new_sentence_data) start = j new_sentence_data = { "text" : text[start: ], "start" : ts_list[start][0 ], "end" : ts_list[-1 ][1 ], "ts_list" : [ts_list[k] for k in range (start, len (ts_list))] } new_sentences.append(new_sentence_data) audio_data, fs = librosa.load(audio_file, sr=target_sr) def get_embedding (audio_data: np.ndarray ): if next (sv_pipline.model.parameters()).device.type != "cuda" : sv_pipline.model.to("cuda" ) output = torch.from_numpy(audio_data).unsqueeze(0 ) output = output.to("cuda" ) with torch.no_grad(): embedding = sv_pipline.model(output) return embedding for sentence in new_sentences: sentence["duration" ] = sentence["end" ] - sentence["start" ] if sentence["duration" ] < min_chunk_length: sentence["speaker_id" ] = -1 continue start_sample = int ((sentence["start" ] / 1000 ) * fs) end_sample = int ((sentence["end" ] / 1000 ) * fs) target_audio_data = audio_data[start_sample: end_sample] embedding = get_embedding(target_audio_data).cpu().numpy() result = speaker_clf.predict_proba(embedding)[0 ] speaker_id, proba = np.argmax(result), max (result) sentence["speaker_id" ], sentence["speaker_proba" ] = speaker_id, proba sentence["speaker" ] = id2speaker[str (speaker_id)] processed_sentences = [] sentence_num_before_processing = len (new_sentences) for i in range (sentence_num_before_processing): if new_sentences[i]["speaker_id" ] == -1 : continue else : processed_sentences.append(new_sentences[i]) basename = os.path.basename(audio_file) basename, ext_name = os.path.splitext(basename) basename = basename.replace("_(Vocals)_UVR-MDX-NET-Voc_FT" , "" ) audio = AudioFileClip(audio_file) j = 0 all_ = len (processed_sentences) for sentence in processed_sentences: start = sentence["start" ] / 1000 end = sentence["end" ] / 1000 speaker = sentence["speaker" ] j += 1 audio_chunk = audio.subclip(start, end) os.makedirs(os.path.join(chunks_dir, speaker), exist_ok=True ) audio_chunk.write_audiofile(f"{os.path.join(chunks_dir, speaker, basename)} _{j} {ext_name} " ) audio.close()
运行enhance_clf.py之后应该能得到一系列长于1s的音频,而且按基础说话人分类的结果将这些音频都归类到不同的说话人文件夹下面了。此时我们需要逐个检查这些文件,将不对应的音频文件(即分类器判断错误的)放入正确的说话人文件夹中。这里有一个需要注意的,如果你发现某个音频是有多个说话人或者是没处理干净的BGM的话,删除该音频避免它在后面混入训练数据中干扰模型。
最后,我们能够将所有音频检查完,得到一个干净的新数据集。重命名该文件夹,比如如果一开始放在/root/data/processed/chunks下的,在完成后可以重命名chunks文件夹为该集首字母的组合(这个随意,只是怕误删掉),比如切分的这一集是“大雄的黑洞”就重命名为dxdhd_chunks。
接下来要将这个新数据集加入到模型中训练一个更好的分类模型,在feature_voice.py中将新数据文件夹加入extra_data_dirs这个列表里即可:
1 2 3 extra_data_dirs = ["/root/data/processed/dxdhd_chunks" ]
再次执行feature_voice.py可以训练一个新的更好的说话人分类模型并进行保存。
做完这章的步骤后,继续切另外的音频文件看看效果,如果效果不满意那就重复上述流程,随着标记数据量的增多,模型的分类错误率应该逐步下降。当我们觉得分类器的分类性能令人满意了之后,我们可以进入最后的一个步骤——组合ASR和说话人分类模型从音频中分离不同说话人。
组合ASR和说话人分类模型从音频中分离不同说话人
最后一步了,我们将上一个步骤训练好的说话人分类模型和ASR模型组合起来,在整个待处理音频文件夹上应用ASR切分+说话人分类。但也有一些和之前不同的地方:
将启发式地处理这些小于1s的音频块,因为这些音频一般是语气词,将其统称为语气片段。如果这个语气片段的左边或右边存在被标记为说话人的音频,而且间隔小于语气词合入极限间隔,那就会就近合入一个说话人中。
会将间隔小于预定义的最大句子间隔而且说话人相同的短句合为一个长句,这样切分的片段听起来更自然。
下面是最后切分脚本的参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 from modelscope.pipelines import pipelinefrom modelscope.utils.constant import Tasksimport joblibimport librosafrom moviepy.editor import AudioFileClipimport numpy as npimport jsonimport osimport globimport torchmax_sentence_interval = 800 max_combine_interval = 100 min_chunk_length = 1000 margin = 0 speaker_clf_path = "说话人识别模型文件夹/clf.joblib" id2speaker_path = "说话人识别模型文件夹/id2speaker.json" target_sr = 16000 audio_path = "需要切分和说话人识别的音频文件夹路径" chunks_dir = "输出的路径 xxx/raw类似的" batch_size_token = 4000 start_pos = 0 inference_pipeline = pipeline( task=Tasks.auto_speech_recognition, model='damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch' ) sv_pipline = pipeline( task='speaker-verification' , model='damo/speech_eres2net_large_sv_zh-cn_3dspeaker_16k' , model_revision='v1.0.0' ) speaker_clf = joblib.load(speaker_clf_path) id2speaker = json.load(open (id2speaker_path)) def get_embedding (audio_data: np.ndarray ): if next (sv_pipline.model.parameters()).device.type != "cuda" : sv_pipline.model.to("cuda" ) output = torch.from_numpy(audio_data).unsqueeze(0 ) output = output.to("cuda" ) with torch.no_grad(): embedding = sv_pipline.model(output) return embedding audio_files = glob.glob(os.path.join(audio_path, "*.wav" )) audio_files = audio_files[start_pos: ] all_num = len (audio_files) for a_i, audio_file in enumerate (audio_files): rec_result = inference_pipeline(audio_in=audio_file, batch_size_token=batch_size_token) new_sentences = [] for sentence in rec_result["sentences" ]: ts_list = sentence["ts_list" ] word_seg_list = sentence["text_seg" ].split(" " )[:-1 ] text = sentence["text" ] start = 0 for i in range (1 , len (ts_list)): if ts_list[i][0 ] - ts_list[i-1 ][1 ] > max_sentence_interval: rest_of_char = i - start new_text = "" for j in range (start, len (text)): if rest_of_char > 0 : new_text += text[j] if text[j] not in ["," , "。" , "!" ]: rest_of_char -= 1 else : break new_sentence_data = { "text" : new_text + "。" , "start" : ts_list[start][0 ], "end" : ts_list[i-1 ][1 ], "ts_list" : [ts_list[k] for k in range (start, i)] } new_sentences.append(new_sentence_data) start = j new_sentence_data = { "text" : text[start: ], "start" : ts_list[start][0 ], "end" : ts_list[-1 ][1 ], "ts_list" : [ts_list[k] for k in range (start, len (ts_list))] } new_sentences.append(new_sentence_data) audio_data, fs = librosa.load(audio_file, sr=target_sr) for sentence in new_sentences: sentence["duration" ] = sentence["end" ] - sentence["start" ] if sentence["duration" ] < min_chunk_length: sentence["speaker_id" ] = -1 continue start_sample = int ((sentence["start" ] / 1000 ) * fs) end_sample = int ((sentence["end" ] / 1000 ) * fs) target_audio_data = audio_data[start_sample: end_sample] embedding = get_embedding(target_audio_data).cpu().numpy() result = speaker_clf.predict_proba(embedding)[0 ] speaker_id, proba = np.argmax(result), max (result) sentence["speaker_id" ], sentence["speaker_proba" ] = speaker_id, proba sentence["speaker" ] = id2speaker[str (speaker_id)] processed_sentences = [] sentence_num_before_processing = len (new_sentences) for i in range (sentence_num_before_processing-1 , -1 , -1 ): if new_sentences[i]["speaker_id" ] == -1 : if i == sentence_num_before_processing - 1 : if new_sentences[i]["start" ] - new_sentences[i-1 ]["end" ] < max_combine_interval and \ new_sentences[i-1 ]["speaker_id" ] != -1 : new_sentences[i-1 ]["end" ] = new_sentences[i]["end" ] new_sentences[i-1 ]["text" ] = new_sentences[i-1 ]["text" ] + new_sentences[i]["text" ] elif i == 0 : if len (processed_sentences) > 0 and len (new_sentences) > 1 and \ processed_sentences[0 ]["start" ] - new_sentences[i]["end" ] < max_combine_interval: processed_sentences[0 ]["start" ] = new_sentences[i]["start" ] processed_sentences[0 ]["text" ] = new_sentences[i]["text" ] + processed_sentences[0 ]["text" ] else : min_duration = max_sentence_interval + 1 min_pos = None if new_sentences[i]["start" ] - new_sentences[i-1 ]["end" ] < max_combine_interval and \ new_sentences[i-1 ]["speaker_id" ] != -1 : min_duration = new_sentences[i]["start" ] - new_sentences[i-1 ]["end" ] min_pos = "left" if len (processed_sentences) > 0 and len (new_sentences) > 1 and \ processed_sentences[0 ]["start" ] - new_sentences[i]["end" ] < max_combine_interval: if processed_sentences[0 ]["start" ] - new_sentences[i]["end" ] < min_duration: min_duration = processed_sentences[0 ]["start" ] - new_sentences[i]["end" ] min_pos = "right" if min_pos is not None : if min_pos == "left" : new_sentences[i-1 ]["end" ] = new_sentences[i]["end" ] new_sentences[i-1 ]["text" ] = new_sentences[i-1 ]["text" ] + new_sentences[i]["text" ] else : processed_sentences[0 ]["start" ] = new_sentences[i]["start" ] processed_sentences[0 ]["text" ] = new_sentences[i]["text" ] + processed_sentences[0 ]["text" ] else : if len (processed_sentences) == 0 : processed_sentences.append(new_sentences[i]) else : if processed_sentences[0 ]["speaker_id" ] == new_sentences[i]["speaker_id" ] and \ processed_sentences[0 ]["start" ] - new_sentences[i]["end" ] < max_sentence_interval: processed_sentences[0 ]["text" ] = new_sentences[i]["text" ] + processed_sentences[0 ]["text" ] processed_sentences[0 ]["start" ] = new_sentences[i]["start" ] else : processed_sentences.insert(0 , new_sentences[i]) basename = os.path.basename(audio_file) basename, ext_name = os.path.splitext(basename) basename = basename.replace("_(Vocals)_UVR-MDX-NET-Voc_FT" , "" ) audio = AudioFileClip(audio_file) j = 0 all_ = len (processed_sentences) for sentence in processed_sentences: start = sentence["start" ] / 1000 end = sentence["end" ] / 1000 speaker = sentence["speaker" ] j += 1 audio_chunk = audio.subclip(start, end) os.makedirs(os.path.join(chunks_dir, speaker), exist_ok=True ) audio_chunk.write_audiofile(f"{os.path.join(chunks_dir, speaker, basename)} _{j} {ext_name} " ) audio.close() print (f"已处理: {a_i + 1 } / {all_num} " ) print ("处理完成!" )
等待处理完成后,应该在chunks变量对应的目录下看到最终的结果了,到这里就已经把音频成功切分并按说话人分好类了,完结撒花。
总结与思考
因为基于聚类的说话人分类比较吃embedding的余弦相似度判别效果,而主要在英文数据集上训练的pyannote对中文音频的判别效果不佳,而且要收集数据微调一个这样的纯音频说话人识别模型难度比较大,所以放弃了基于纯音频方案的分割。
作为替代,使用了ASR转录出来的文本信息中的语义停顿符号作为分割依据,这在一定程度上缓解了多说话人音频分割不准确的问题。然而基于语义信息的切分依然受到转录文本质量、标点符号生成质量和字级时间戳模型对齐精度的影响,尤其是时间戳对齐不准确的问题会导致音频提前开始或提早结束,这影响了切分后音频的质量。因此,这个方法目前来说的累计误差还是比较大的,还存在性能提升空间。并且它并不能处理多说话人说话重叠的问题,这似乎是这个方案的硬伤。
分割好了音频片段后,使用渐进式训练的方式通过人类反馈提升说话人分类模型的性能。在人类的监督下,有监督的说话人分离模型的表现应该远远好于基于聚类算法的说话人分类效果。同时,因为是渐进式地提升模型分类效果,所以理论上越到渐进式训练的后期需要人类调整的错误样本就越少,这有助于减少人类标注的时间成本。
这个流程仍然有一些值得思考的地方:
在最开始训练说话人分类基础模型时,纯粹依赖于手工挑选样本,这样非常的枯燥而且消耗人力。在这个步骤里面如果先聚类,通过聚类算法把相似的音频合在一堆然后再让人来挑选会不会能节省工作量。
在embedding后面接LDA模型(线性判别模型)完成说话人分类是因为我觉得它优化的原理来自“最大化类间距离,最小化类内距离”,这样的效果就好像是一个引入人类监督的“聚类算法”。通过LDA找到某个线性子空间,然后将样本投影到这个空间后就能发现不同说话人的音频数据点形成不同的团簇。这样降维的做法比较符合直觉,假设提取的音频embedding里包含了说话人详细的音色信息,但如果我们只需要分类男声和女声,那么其实很多音色信息都是冗余的而且可能带来误判,如果通过LDA裁剪这些高维的信息丰富的embedding到我们任务相关的低维空间,这样应该能在利用预训练的embedding和收集的任务相关的训练样本中得到一个比较好的平衡。但随着可用训练样本的增多,会不会使用更复杂的分类器,如随机森林、XGBoost能得到更稳定更好的效果呢?
以上就是全部内容了,非常感谢这些音频领域的研究者们开放了这么多有价值的预训练模型!