重新认识CLIP文本侧编码器
CLIP模型,对于关注近几年深度学习发展的同学肯定是不陌生的。CLIP虽然名义上属于多模态领域,可是其大力出奇迹的出圈程度让很多不是这个方向的人也了解了这个模型。CLIP的核心思想很简单:通过文本编码器对文本进行编码,然后再通过图像编码器对图像进行编码,之后将两个编码向量点乘并使用对比损失优化文本编码器和图像编码器。用CLIP论文里的一幅图就能很清晰地描述它:
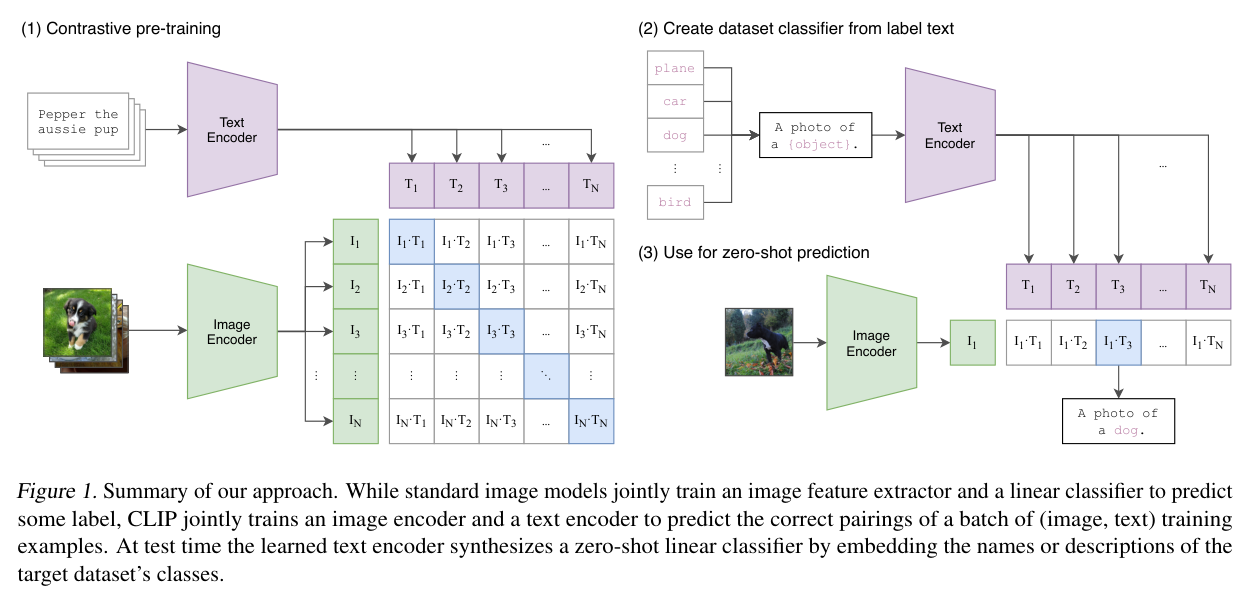
但今天要讨论的主题不是CLIP模型和它使用大规模图文对+对比学习实现很强的Zero Shot能力,而是在那个看似平平无奇的Text Encoder,在上图里它是一个紫色的梯形。文本通过这个编码器被编码为文本特征向量。
CLIP的文本编码器
如果粗看这副图不看论文的话,我们能大概想象出这个Encoder大概是像BERT一样,采用双向自注意力机制,然后取[CLS]标记(也就是每句话开头插入的那个标记)对应的向量作为文本特征向量。但很不幸,这个猜想是错误的,而且如果我们保持这样的看法的话很可能会错误地使用CLIP。
事实上,这个文本编码器是一个GPT-2结构的模型。这个模型使用的不是BERT类似的双向自注意力机制,而是因果注意力机制。所谓的因果注意力机制,就是通过设计attention_mask使得当前的Token只能看到在它和它的左边的Token,而不能看到右边的任何Token。比如:“你吃饭了吗”这句话,如果当前Token是“吃饭”,那它能看到的Token就是[SOS]、"你"和“吃饭”,“了”和“吗”它是看不到的。在GPT中,这样方便模型进行自回归式地预测下一个单词的预训练。因为当前Token都看不到下一个Token,于是只需要向前运算一次就能获取整个句子自回归式的预测下一个单词的结果,大大提高了训练效率。
回到之前的话题,如果我们按原先的想法取开头的第一个[CLS]标记对应的向量作为文本特征向量的话,因为这个标记在开头,由于因果注意力机制的存在,所以这个标记除了看到它自己之外并不能看到任何文本数据!这相当地糟糕,在BERT模型中习以为常的事放在CLIP的文本编码器中将犯下致命的错误,你会提取到一个几乎不包含任何文本数据信息的向量。
但如果认真阅读了论文,作者是写了正确的文本特征提取方法的,引用一段原论文:
The text encoder is a Transformer (Vaswani et al., 2017) with the architecture modifications described in Radford et al. (2019). As a base size we use a 63M-parameter 12layer 512-wide model with 8 attention heads. The transformer operates on a lower-cased byte pair encoding (BPE) representation of the text with a 49,152 vocab size (Sennrich et al., 2015). For computational efficiency, the max sequence length was capped at 76. The text sequence is bracketed with [SOS] and [EOS] tokens and the activations of the highest layer of the transformer at the [EOS] token are treated as the feature representation of the text which is layer normalized and then linearly projected into the multi-modal embedding space. Masked self-attention was used in the text encoder to preserve the ability to initialize with a pre-trained language model or add language modeling as an auxiliary objective, though exploration of this is left as future work.
注意加粗的部分,意思就是[EOS]标签对应的特征向量才是文本的特征。好了,本文要说的核心也就是这个,需要使用第一个[EOS]标记而不是所谓的[SOS]/[CLS]标记对应的向量作为整个文本的特征向量,因为CLIP模型的文本编码器实际上是一个重新随机初始化参数的GPT-2模型。
GPT-2模型做编码器?
在刻板印象里,GPT-1是只有Decoder结构的Transformer模型,擅长生成任务而在文本理解任务上弱于同等大小的BERT,而GPT-2则是GPT-1的规模放大版,理应也是解码器架构而且更擅长生成任务。但是不擅长归不擅长,并不是不能做,Huggingface的文档里从GPT-1就开始有专门的为GPT系列做序列分类任务的模型了,其原理就是使用句子结束的标记代表整个句子,因为这个标记在因果注意力下刚好能看完整个句子,进而完成分类任务。
因此,虽然GPT模型是解码器架构,但只要取最后的[EOS]标记作为整个句子的表示,它是可以看到整句话的,也就是说纯解码器架构不妨碍它编码整个句子。
那可能会有疑惑,能看到整个句子就行吗?[EOS]代表整句话的终止符,在GPT的自回归预训练里实际是没有对这个标记进行任何预训练的哦,会不会享受不到预训练的光环效果。实际不是的,就预训练过程来说[EOS]标记的确没有起除作为结尾标记之外的作用,但是模型能在预训练里学到前文的语义信息呀!所以当迁移到下游任务时,[EOS]这个位置恰好能看到前面所有文段的语义信息,在反向传播中就可以从数据中学到解决问题的特征。退一步来说,移除下一句预测的RoBERTa模型里,[CLS]或者[s]标记对预训练来说也是无关紧要的,毕竟就预测[MASK]遮住的标记嘛。但是一旦迁移到下游任务,任何句子开头都有个[CLS]标签,通过双向注意力机制可以看到整个句子的语义信息,这样就也可以在微调里学到下游任务的知识。
总结来说,对于语言模型,解码器和编码器去表征整段文本都是可行的。关键在于对应特征向量标记的选取,只要这个标记能够看到整段文本,那就有作为文本向量表示标记的潜力。至于CLIP为啥要用GPT-2的架构,因为这个文本编码器也没有预训练所以不存在说要适应自回归然后才用GPT架构,我感觉可能也是因为GPT系列是openai自己的项目,构建起来比较顺手于是就用了。也可能是本来是用了预训练的GPT模型,然后在4亿图文对上对比学习后发现相比从头开始训练的增益不大或者负增益,之后才随机初始化的,也没有换架构。
其他的CLIP变种的文本编码器呢?
openai开源了CLIP的模型代码和预训练模型权重,然而对于预训练的那4亿图文对是没有开源的,这使得结果无法复现。于是,除了官方CLIP实现外就也有一些CLIP的变种实现,比较有名的就是OpenCLIP和ChineseCLIP了(个人感觉)。我们后续的讨论主要也还是基于HuggingFace上的这些变种的实现,这样可能比较好比较。
OpenCLIP里我比较感兴趣的就是LAION在他们发布的超大数据集LAION-2B上训练的CLIP,号称最大最强的OpenCLIP模型。我找了一下HuggingFace上的laion/CLIP-ViT-H-14-laion2B-s32B-b79K,laion/CLIP-ViT-B-32-laion2B-s34B-b79K等模型,发现其实实现都和openai的CLIP共用的一个模型。也就是说,这些模型都是GPT-2架构当文本编码器,ViT架构当图像编码器的CLIP模型。
但实际就OpenCLIP项目本身,是提供了使用各种文本编码器的机会的,尤其是支持使用HuggingFace的各种编码器模型,可以见文件/src/open_clip/hf_configs.py:
1 | # HF architecture dict: |
可以看到,在open_clip的默认设置中,对于roberta和t5类的模型,都是使用的平均池化来代表整个文本的特征的。而对于bert模型,则是用到[CLS]对应的向量代表整个文本的特征。
最后说一下ChineseCLIP,这个就是货真价实地拿非GPT-2模型做文本编码器打了个样,ChineseCLIP的文本编码器都是中文的RoBERTa模型,然后是拿第一个标记,也即[CLS]标记作为整段中文句子的标记的。这比较符合我们的直觉,甚至我觉得好像CLIP就应该是这样子的才对...
总结一下,就是用laion预训练的OpenCLIP的话,它依旧和CLIP一样文本编码器是GPT架构,记得取最后一个位置的向量作为整个文本的表示。如果是用的ChineseCLIP,它的文本编码器是RoBERTa,使用[CLS]标记没问题。如果是其他的人训练的其他CLIP模型,那就得留心一下了,可能是结束标记、开始标记或者平均池化。
从CLIP文本编码器到文本嵌入
CLIP文本编码器就是想把一段文本映射到一个和图像统一的向量空间,在这个空间中完成图文的相似度计算。在文本单模态领域,这样的需求也不少,比如搜索引擎检索资料时我们希望语义越相关的结果越靠前,这样搜索精确率提高,对使用者来说就更有效率。
专对于文本来说,Sentence
Transformers是解决语句相似度的一个比较成熟的库。有意思的是,受欢迎的sentence-transformers/all-MiniLM-L6-v2模型就是对模型输出进行平均池化后作为整个句子的表示的,说明这个找一个向量作为整个文本的表示的工作还不是那么统一,结束标记、开始标记或者平均池化的都有,总之它们都差不多能满足需求。但是这其中的优劣就不知道了,也许有人研究过,也许尚待研究。
CLIP文本编码器的新出路
前面一直都说这个文本编码器实际上是GPT-2,那能不能真的加个自回归让它也训练着呢?laion的coca就想这样做,博客地址:链接。该模型在 CLIP 对比目标之上添加了一个自回归目标(生成)。该架构由三部分组成,前两部分类似于组成 CLIP 模型的部分,第三部分是位于文本编码器之上的文本解码器。附加解码器将编码图像(通过交叉注意力)和先前的标记作为输入来预测下一个最可能的标记。
源代码中的位置
记录一下上面的说法在源代码中的位置,以便后续查找。
- laion和openai的CLIP都是共享的这个实现:
1 | # transformers/src/transformers/models/clip/modeling_clip.py#737 |
- Chinese_CLIP的实现:
1 | # transformers/src/transformers/models/clip/modeling_chinese_clip.py |
总结
感觉写了一个世纪,但是应该把事情说清楚了。核心问题就是CLIP的文本编码器实际是一个解码器架构的GPT模型,然后因为因果注意力的关系不可以用第一个token做特征向量,而是要用[EOS]对应的作为特征向量。而对于其他的CLIP实现,它是有可能不用GPT这样的模型的,因此具体问题具体分析。
最后,在写代码的时候里你实在不想关心,或者就是要适配很多不同的CLIP,就看看有没有啥encode_text或者get_text_features之类的方法,这个肯定是通用而且能拿对的。