论文分享-基于提示的多模态仇恨迷因分类
Overview
Prompting for Multimodal Hateful Meme Classification(基于提示的多模态仇恨迷因分类)是多模态迷因分类方向的一篇论文,该论文发表于2022年的EMNLP会议上。论文地址

Introduction
进行多模态仇恨迷因检测的意义?
互联网迷因(Internet memes)已经发展成为社交媒体上最受欢迎的交流形式之一。迷因是以附带文本的图像形式呈现的,通常是为了搞笑或者讽刺。然而,恶意网络用户在幽默的幌子下创作和分享有仇恨性的迷因,这些迷因会基于种族、宗教等特定特征攻击和仇视某些群体。
这些仇恨迷因也继承了互联网迷因病毒式传播的特性,仇恨迷因比纯文本的网络仇恨言论对社会威胁更大,用户可以在更多的对话或者语境中转发这些仇恨迷因。因此,如何检测仇恨迷因并打击仇恨迷因的传播是具有现实意义的问题。
多模态仇恨迷因检测面临哪些挑战?
仇恨迷因检测时一项具有挑战性的多模态分类任务。因为性能优秀的解决方案需要跨视觉和文本模态来理解和推理迷因想要表达的意思,在分类时,可能还需要背景知识来辅助对迷因含义的推理。
- 需要跨文本和视觉模态收集信息推理迷因想表达的含义
- 需要背景知识辅助迷因的推理
Related Work
仇恨迷因检测
仇恨迷因分类时一个新兴的多模态任务,因为最近发布了一些公开可获取的迷因数据集而流行起来。迷因的特殊构造使得单模态方法在分类任务里性能不佳,因此现有研究大多采用多模态的方法对仇恨模因进行分类。主要可以分为以下两大类方法:
- 提取单模态特征之后进行特征融合(双流模型、基于注意力的融合等)
- 微调大规模预训练的多模态模型
然而,这些方法都没有能很好融合迷因背后的背景知识进行分类。
语言模型的提示学习
诸如GPT、BERT、RoBERTa等大型预训练语言模型的流行也促进了提示学习的发展。现有的提示学习研究已经探索了使用预训练语言模型作为隐式的和非结构化的知识库。最近的研究也表明提示学习可用促使预训练语言模型完成各种NLP任务,如情感分析和自然语言推断,并且在小样本上能产生良好的性能。
然而,现有的提示学习研究大多局限于单模态任务,关于多模态任务的提示学习研究较少。
Motivation
现有的多模态仇恨迷因分类研究不足以对仇恨模因中编码的背景知识进行建模,而预训练语言模型通过提示学习可以利用其非结构化的隐性知识对仇恨迷因的背景知识进行补充。
因此,作者想通过在多模态任务上对预训练语言模型实现提示学习进行仇恨迷因的分类,提出了一个通过提示学习的RoBERTa模型进行多模态仇恨迷因分类的框架PromptHate。
Method
整体框架
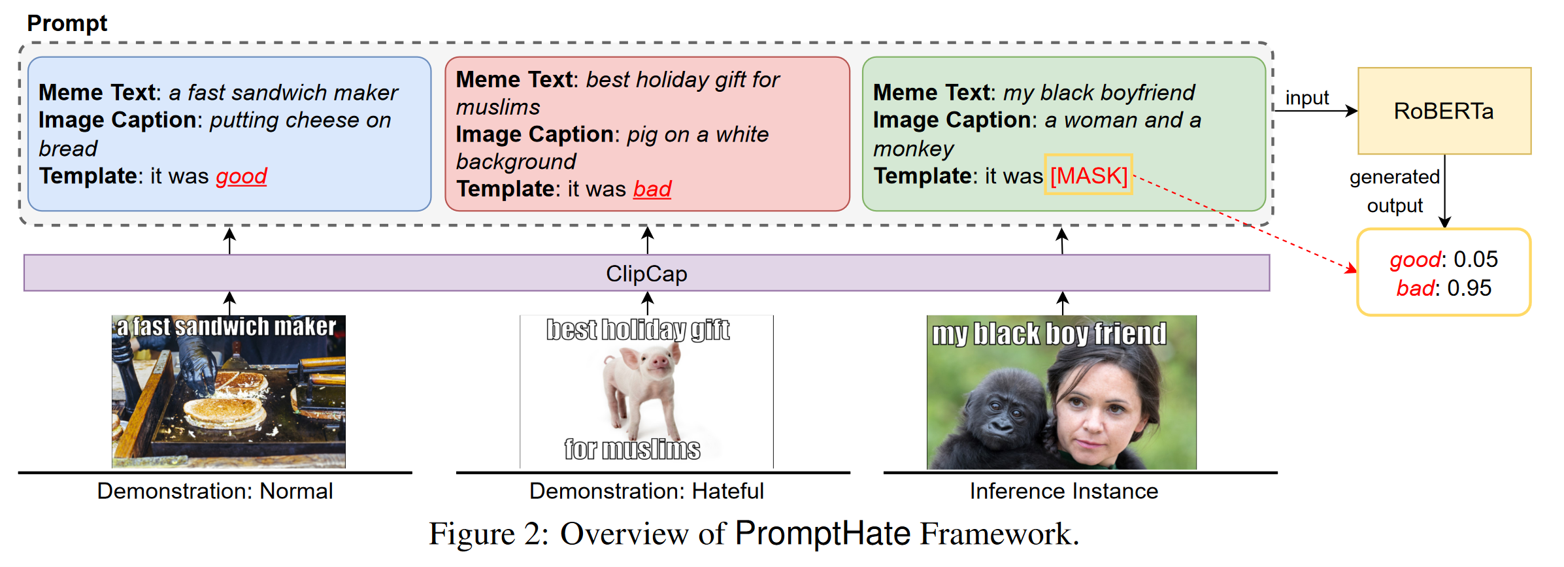
具体的处理步骤可以被描述为以下4步:
首先使用开源Python包EasyOCR提取模因中的文本, 然后使用MMEditing进行in-painting以删除图像中的文本。
ClipCap能够为低分辨率的网络图像生成高质量的描述。生成的标题倾向于描述模因图像中的主要对象或事件,我们使用这些标题作为PromptHate模型的输入。
除了图片描述 ,我们还利用谷歌视觉Web实体检测API和预先训练的FairFace分类器(Kärkkäinen and Joo, 2019)来提取模因中的实体和人口统计信息(如果模因包含一个人)。 提取的实体和人口信息被用作补充信息,将与图像说明文字相结合,作为PLM的输入。
最后,采用手动定义的标签词和提示模板进行提示学习。
Multi-Query Ensemble
在提示模板中的正面和负面示例可以为推断当前实例提供额外的信息,从直觉上讲,精心选择与需要推断的实例接近的迷因可以带来更加丰富的信息。
但这样的选择并不容易,因此作者使用了多对演示示例来构建提示模板,具体来说,使用M-query集成策略,用M对提示模板来预测推理实例,然后将所有模板的预测分数取平均作为最终的预测分数。这样通过多对示例可以比单对示例提供更加多样化的信息。 \[ y_{final} = \frac{1}{M} \sum^M_{m=1}{y_m} \]
Experiments
Dataset
论文使用了两个公开的数据集:
Facebook发布的Facebook Hateful Meme(FHM)数据集。该数据集主要包含Facebook构建和发布的涉及多个领域的仇恨迷因数据集。
Pramanick等人发布的Harmful Meme(HarM)数据集。该数据集主要包含收集自推特的与Covid-19相关的表情包。
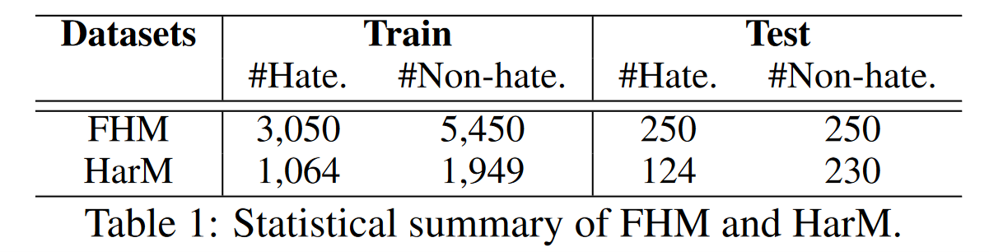
数据集的统计信息如下:
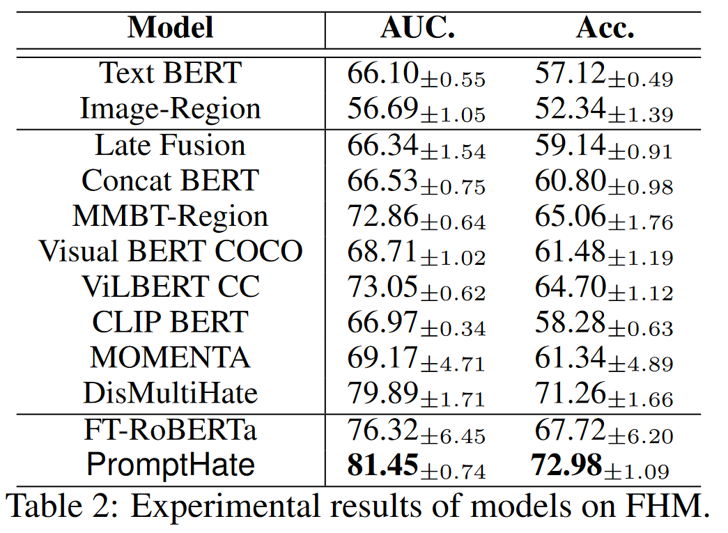
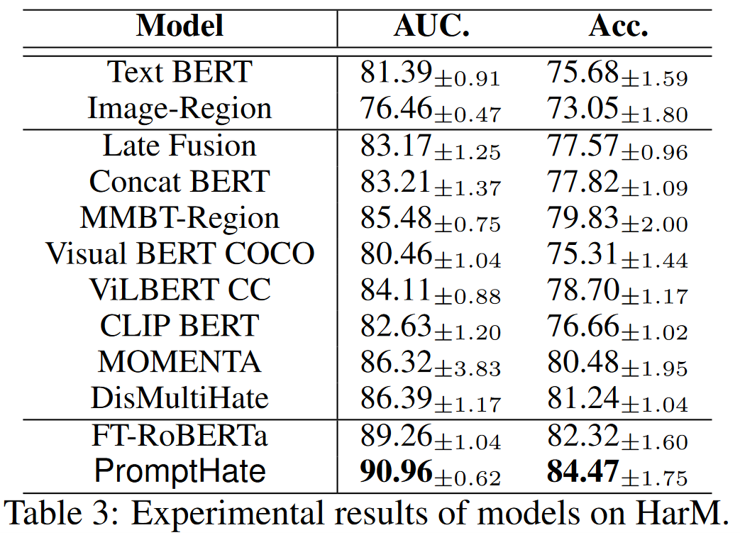
Result
Conclusion
作者提出了PromptHate,这是一个简单而有效的基于提示的多模态分类框架,可以通过提示模板驱动预训练语言模型进行仇恨迷因分类。在两个公开数据集上的评估表明,PromptHate优于最先进的基线。
但同时作者也注意到PromptHate仍然有局限性。在未来的工作中,作者将探索如何为推理实例选择更好的示例的策略,并添加推理模块来提高PromptHate对预训练语言模型中隐式知识的利用。